Ascend
OSC's Ascend cluster was installed in fall 2022 and is a Dell-built, AMD EPYC™ CPUs with NVIDIA A100 80GB GPUs cluster devoted entirely to intensive GPU processing.
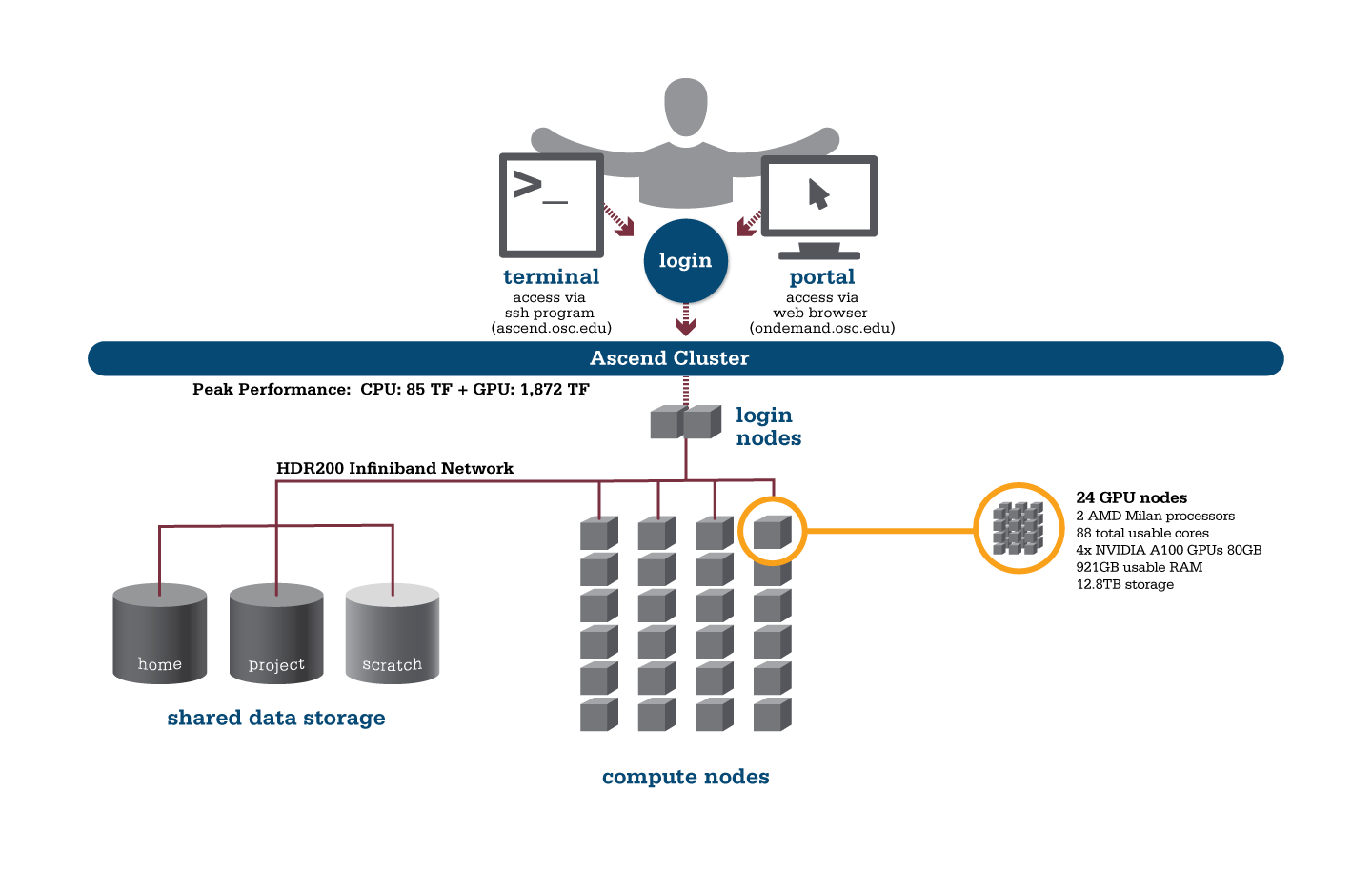
Hardware

Detailed system specifications:
- 24 Power Edge XE 8545 nodes, each with:
- 2 AMD EPYC 7643 (Milan) processors (2.3 GHz, each with 44 usable cores)
- 4 NVIDIA A100 GPUs with 80GB memory each, supercharged by NVIDIA NVLink
- 921GB usable RAM
- 12.8TB NVMe internal storage
- 2,112 total usable cores
- 88 cores/node & 921GB of memory/node
- Mellanox/NVIDA 200 Gbps HDR InfiniBand
- Theoretical system peak performance
- 1.95 petaflops
- 2 login nodes
- IP address: 192.148.247.[180-181]
How to Connect
-
SSH Method
To login to Ascend at OSC, ssh to the following hostname:
ascend.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@ascend.osc.edu
You may see a warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprints listed here, then type yes.
From there, you are connected to the Ascend login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Ascend at OSC with our OnDemand tool. The first step is to log into OnDemand. Then once logged in you can access Ascend by clicking on "Clusters", and then selecting ">_Ascend Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
File Systems
Ascend accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the old clusters. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system on Ascend is the same as on the Owens and Pitzer systems. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider .
You can keep up to the software packages that have been made available on Ascend by viewing the Software by System page and selecting the Ascend system.
Batch Specifics
Refer to this Slurm migration page to understand how to use Slurm on the Ascend cluster.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Ascend Programming Environment
Compilers
C, C++ and Fortran are supported on the Ascend cluster. Intel, oneAPI, GNU, nvhpc, and aocc compiler suites are available. The Intel development tool chain is loaded by default. Compiler commands and recommended options for serial programs are listed in the table below. See also our compilation guide.
The Milan processors from AMD that make up Ascend support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use. However, bare in mind that clock speeds decrease as the level of the instruction set increases. So, if your code does not benefit from vectorization it may be beneficial to use a lower instruction set.
In our experience, the Intel compiler usually does the best job of optimizing numerical codes and we recommend that you give it a try if you’ve been using another compiler.
With the Intel compilers, use -xHost and -O2 or higher. With the GNU compilers, use -march=native and -O3.
This advice assumes that you are building and running your code on Ascend. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
| LANGUAGE | INTEL | GNU |
|---|---|---|
| C | icc -O2 -xHost hello.c | gcc -O3 -march=native hello.c |
| Fortran 77/90 | ifort -O2 -xHost hello.F | gfortran -O3 -march=native hello.F |
| C++ | icpc -O2 -xHost hello.cpp | g++ -O3 -march=native hello.cpp |
Parallel Programming
MPI
OSC systems use the MVAPICH2 implementation of the Message Passing Interface (MPI), optimized for the high-speed Infiniband interconnect. MPI is a standard library for performing parallel processing using a distributed-memory model. For more information on building your MPI codes, please visit the MPI Library documentation.
MPI programs are started with the srun command. For example,
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=84
srun [ options ] mpi_prog
The srun command will normally spawn one MPI process per task requested in a Slurm batch job. Use the -n ntasks and/or --ntasks-per-node=n option to change that behavior. For example,
#!/bin/bash #SBATCH --nodes=2 # Use the maximum number of CPUs of two nodes srun ./mpi_prog # Run 8 processes per node srun -n 16 --ntasks-per-node=8 ./mpi_prog
The table below shows some commonly used options. Use srun -help for more information.
| OPTION | COMMENT |
|---|---|
-n, --ntasks=ntasks |
total number of tasks to run |
--ntasks-per-node=n |
number of tasks to invoke on each node |
-help |
Get a list of available options |
srun in any circumstances.OpenMP
The Intel, and GNU compilers understand the OpenMP set of directives, which support multithreaded programming. For more information on building OpenMP codes on OSC systems, please visit the OpenMP documentation.
An OpenMP program by default will use a number of threads equal to the number of CPUs requested in a Slurm batch job. To use a different number of threads, set the environment variable OMP_NUM_THREADS. For example,
#!/bin/bash #SBATCH --ntasks=8 # Run 8 threads ./omp_prog # Run 4 threads export OMP_NUM_THREADS=4 ./omp_prog
Interactive job only
Please use -c, --cpus-per-task=X instead of -n, --ntasks=X to request an interactive job. Both result in an interactive job with X CPUs available but only the former option automatically assigns the correct number of threads to the OpenMP program. If the option --ntasks is used only, the OpenMP program will use one thread or all threads will be bound to one CPU core.
Hybrid (MPI + OpenMP)
An example of running a job for hybrid code:
#!/bin/bash #SBATCH --nodes=2 #SBATCH --ntasks-per-node=80 # Run 4 MPI processes on each node and 40 OpenMP threads spawned from a MPI process export OMP_NUM_THREADS=40 srun -n 8 -c 40 --ntasks-per-node=4 ./hybrid_prog
Tuning Parallel Program Performance: Process/Thread Placement
To get the maximum performance, it is important to make sure that processes/threads are located as close as possible to their data, and as close as possible to each other if they need to work on the same piece of data, with given the arrangement of node, sockets, and cores, with different access to RAM and caches.
While cache and memory contention between threads/processes are an issue, it is best to use scatter distribution for code.
Processes and threads are placed differently depending on the computing resources you requste and the compiler and MPI implementation used to compile your code. For the former, see the above examples to learn how to run a job on exclusive nodes. For the latter, this section summarizes the default behavior and how to modify placement.
OpenMP only
For all two compilers (Intel, GNU), purely threaded codes do not bind to particular CPU cores by default. In other words, it is possible that multiple threads are bound to the same CPU core.
The following table describes how to modify the default placements for pure threaded code:
| DISTRIBUTION | Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place threads close to each other as possible in successive order | Distribute threads as evenly as possible across sockets |
| INTEL | KMP_AFFINITY=compact | KMP_AFFINITY=scatter |
| GNU | OMP_PROC_BIND=true OMP_PLACE=cores |
OMP_PROC_BIND=true OMP_PLACE="{0},{48},{1},{49},..."[1] |
- The core IDs on the first and second sockets start with 0 and 48, respectively.
MPI Only
For MPI-only codes, MVAPICH2 first binds as many processes as possible on one socket, then allocates the remaining processes on the second socket so that consecutive tasks are near each other. Intel MPI and OpenMPI alternately bind processes on socket 1, socket 2, socket 1, socket 2 etc, as cyclic distribution.
For process distribution across nodes, all MPIs first bind as many processes as possible on one node, then allocates the remaining processes on the second node.
The following table describe how to modify the default placements on single node for MPI-only code with the command srun:
| DISTRIBUTION (single node) |
Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place processs close to each other as possible in successive order | Distribute process as evenly as possible across sockets |
| MVAPICH2[1] | Default | MV2_CPU_BINDING_POLICY=scatter |
| INTEL MPI | srun --ntasks=84 --cpu-bind="map_cpu:$(seq -s, 0 43),$(seq -s, 48 95)" | Default |
| OPENMPI | srun --ntasks=84 --cpu-bind="map_cpu:$(seq -s, 0 43),$(seq -s, 48 95)" | Default |
MV2_CPU_BINDING_POLICYwill not work ifMV2_ENABLE_AFFINITY=0is set.
To distribute processes evenly across nodes, please set SLURM_DISTRIBUTION=cyclic.
Hybrid (MPI + OpenMP)
For Hybrid codes, each MPI process is allocated OMP_NUM_THREADS cores and the threads of each process are bound to those cores. All MPI processes (as well as the threads bound to the process) behave as we describe in the previous sections. It means the threads spawned from a MPI process might be bound to the same core. To change the default process/thread placmements, please refer to the tables above.
Summary
The above tables list the most commonly used settings for process/thread placement. Some compilers and Intel libraries may have additional options for process and thread placement beyond those mentioned on this page. For more information on a specific compiler/library, check the more detailed documentation for that library.
GPU Programming
96 NVIDIA A100 GPUs are available on Ascend. Please visit our GPU documentation.
Reference
Batch Limit Rules
Memory limit
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs.
Summary
| Node type | default memory per core (GB) | max usable memory per node (GB) |
|---|---|---|
| gpu (4 gpus) - 88 cores | 10.4726 GB | 921.5937 GB |
It is recommended to let the default memory apply unless more control over memory is needed.
Note that if an entire node is requested, then the job is automatically granted the entire node's main memory. On the other hand, if a partial node is requested, then memory is granted based on the default memory per core.
See a more detailed explanation below.
Default memory limits
A job can request resources and allow the default memory to apply. If a job requires 300 GB for example:
#SBATCH --ntasks=1 #SBATCH --cpus-per-task=30
This requests 30 cores, and each core will automatically be allocated 10.4 GB of memory (30 core * 10 GB memory = 300 GB memory).
Explicit memory requests
If needed, an explicit memory request can be added:
#SBATCH --ntasks=1 #SBATCH --cpus-per-task=4 #SBATCH --mem=300G
See Job and storage charging for details.
CPU only jobs
Dense gpu nodes on Ascend have 88 cores each. However, cpuonly partition jobs may only request 84 cores per node.
An example request would look like:
#!/bin/bash #SBATCH --partition=cpuonly #SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks=2 #SBATCH --cpus-per-task=42 # requests 2 tasks * 42 cores each = 84 cores <snip>
GPU Jobs
Jobs may request only parts of gpu node. These jobs may request up to the total cores on the node (88 cores).
Requests two gpus for one task:
#SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks=1 #SBATCH --cpus-per-task=20 #SBATCH --gpus-per-task=2
Requests two gpus, one for each task:
#SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks=2 #SBATCH --cpus-per-task=10 #SBATCH --gpus-per-task=1
Of course, jobs can request all the gpus of a dense gpu node as well. These jobs have access to all cores as well.
Request an entire dense gpu node:
#SBATCH --nodes=1 #SBATCH --ntasks=1 #SBATCH --cpus-per-task=88 #SBATCH --gpus-per-node=4
Partition time and job size limits
Here is the walltime and node limits per job for different queues/partitions available on Ascend:
|
NAME |
MAX TIME LIMIT |
MIN JOB SIZE |
MAX JOB SIZE |
NOTES |
|---|---|---|---|---|
|
cpuonly |
4-00:00:00 |
1 core |
4 nodes |
This partition may not request gpus 84 cores per node only |
| gpu |
7-00:00:00 |
1 core |
4 nodes |
|
| debug | 1:00:00 | 1 core | 2 nodes |
Usually, you do not need to specify the partition for a job and the scheduler will assign the right partition based on the requested resources. To specify a partition for a job, either add the flag --partition=<partition-name> to the sbatch command at submission time or add this line to the job script:#SBATCH --paritition=<partition-name>
Job/Core Limits
| Max Running Job Limit | Max Core/Processor Limit | Max GPU limit | ||
|---|---|---|---|---|
| For all types | GPU debug jobs | For all types | ||
| Individual User | 256 | 4 |
704 |
32 |
| Project/Group | 512 | n/a | 704 | 32 |
An individual user can have up to the max concurrently running jobs and/or up to the max processors/cores in use. However, among all the users in a particular group/project, they can have up to the max concurrently running jobs and/or up to the max processors/cores in use.
Migrating jobs from other clusters
This page includes a summary of differences to keep in mind when migrating jobs from other clusters to Ascend.
Guidance for Pitzer Users
Hardware Specifications
| Ascend (PER NODE) | Pitzer (PER NODE) | ||
|---|---|---|---|
| Regular compute node | n/a |
40 cores and 192GB of RAM 48 cores and 192GB of RAM |
|
| Huge memory node |
n/a |
48 cores and 768GB of RAM (12 nodes in this class) 80 cores and 3.0 TB of RAM (4 nodes in this class) |
|
| GPU Node |
88 cores and 921GB RAM 4 GPUs per node (24 nodes in this class) |
40 cores and 192GB of RAM, 2 GPUs per node (32 nodes in this class) 48 cores and 192GB of RAM, 2 GPUs per node (42 nodes in this class) |
|
Guidance for Owens Users
Hardware Specifications
| Ascend (PER NODE) | Owens (PER NODE) | ||
|---|---|---|---|
| Regular compute node | n/a | 28 cores and 125GB of RAM | |
| Huge memory node | n/a |
48 cores and 1.5TB of RAM (16 nodes in this class) |
|
| GPU node |
88 cores and 921GB RAM 4 GPUs per node (24 nodes in this class) |
28 cores and 125GB of RAM, 1 GPU per node (160 nodes in this class) |
|
File Systems
Ascend accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory, project space, and scratch space as on the other clusters.
Software Environment
Ascend uses the same module system as other OSC Clusters.
Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider .
You can keep up to on the software packages that have been made available on Ascend by viewing the Software by System page and selecting the Ascend system.
Programming Environment
C, C++ and Fortran are supported on the Ascend cluster. Intel, oneAPI, GNU, nvhpc, and aocc compiler suites are available. The Intel development tool chain is loaded by default. To switch to a different compiler, use module swap . Ascend also uses the MVAPICH2 implementation of the Message Passing Interface (MPI).
See the Ascend Programming Environment page for details.
Ascend SSH key fingerprints
These are the public key fingerprints for Ascend:
ascend: ssh_host_rsa_key.pub = 2f:ad:ee:99:5a:f4:7f:0d:58:8f:d1:70:9d:e4:f4:16
ascend: ssh_host_ed25519_key.pub = 6b:0e:f1:fb:10:da:8c:0b:36:12:04:57:2b:2c:2b:4d
ascend: ssh_host_ecdsa_key.pub = f4:6f:b5:d2:fa:96:02:73:9a:40:5e:cf:ad:6d:19:e5
These are the SHA256 hashes:
ascend: ssh_host_rsa_key.pub = SHA256:4l25PJOI9sDUaz9NjUJ9z/GIiw0QV/h86DOoudzk4oQ
ascend: ssh_host_ed25519_key.pub = SHA256:pvz/XrtS+PPv4nsn6G10Nfc7yM7CtWoTnkgQwz+WmNY
ascend: ssh_host_ecdsa_key.pub = SHA256:giMUelxDSD8BTWwyECO10SCohi3ahLPBtkL2qJ3l080
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Ascend, please use the following Archival Resource Key:
ark:/19495/hpc3ww9d
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2022. Ascend Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:/19495/hpc3ww9d
Here is the citation in BibTeX format:
@misc{Ascend2022,
ark = {ark:/19495/hpc3ww9d},
url = {http://osc.edu/ark:/19495/hpc3ww9d},
year = {2022},
author = {Ohio Supercomputer Center},
title = {Ascend Supercomputer}
}
And in EndNote format:
%0 Generic %T Ascend Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc3ww9d %U http://osc.edu/ark:/19495/hpc3ww9d %D 2022
Request access
Users who would like to use the Ascend cluster will need to request access. This is because of the particulars of the Ascend environment, which includes its size, GPUs, and scheduling policies.
Motivation
Access to Ascend is done on a case by case basis because:
- All nodes on Ascend are with 4 GPUs, and therefore it favors GPU work instead of CPU-only work
- It is a smaller machine than Pitzer and Owens, and thus has limited space for users
Good Ascend Workload Characteristics
Those interested in using Ascend should check that their work is well suited for it by using the following list. Ideal workloads will exhibit one or more of the following characteristics:
- Needs access to Ascend specific hardware (GPUs, or AMD)
- Software:
- Supports GPUs
- Takes advantage of:
- Long vector length
- Higher core count
- Improved memory bandwidth
Applying for Access
PIs of groups that would like to be considered for Ascend access should send the following in a email to OSC Help:
- Name
- Username
- Project code (group)
- Software/packages used on Ascend
- Evidence of workload being well suited for Ascend
Technical Specifications
The following are technical specifications for Ascend.
- Number of Nodes
-
24 nodes
- Number of CPU Sockets
-
48 (2 sockets/node)
- Number of CPU Cores
-
2,304 (96 cores/node)
- Cores Per Node
-
96 cores/node (88 usable cores/node)
- Internal Storage
-
12.8 TB NVMe internal storage
- Compute CPU Specifications
-
AMD EPYC 7643 (Milan) processors for compute
- 2.3 GHz
- 48 cores per processor
- Computer Server Specifications
-
24 Dell XE8545 servers
- Accelerator Specifications
-
4 NVIDIA A100 GPUs with 80GB memory each, supercharged by NVIDIA NVLink
- Number of Accelerator Nodes
-
24 total
- Total Memory
- ~ 24 TB
- Physical Memory Per Node
-
1 TB
- Physical Memory Per Core
-
10.6 GB
- Interconnect
-
Mellanox/NVIDA 200 Gbps HDR InfiniBand