Oakley
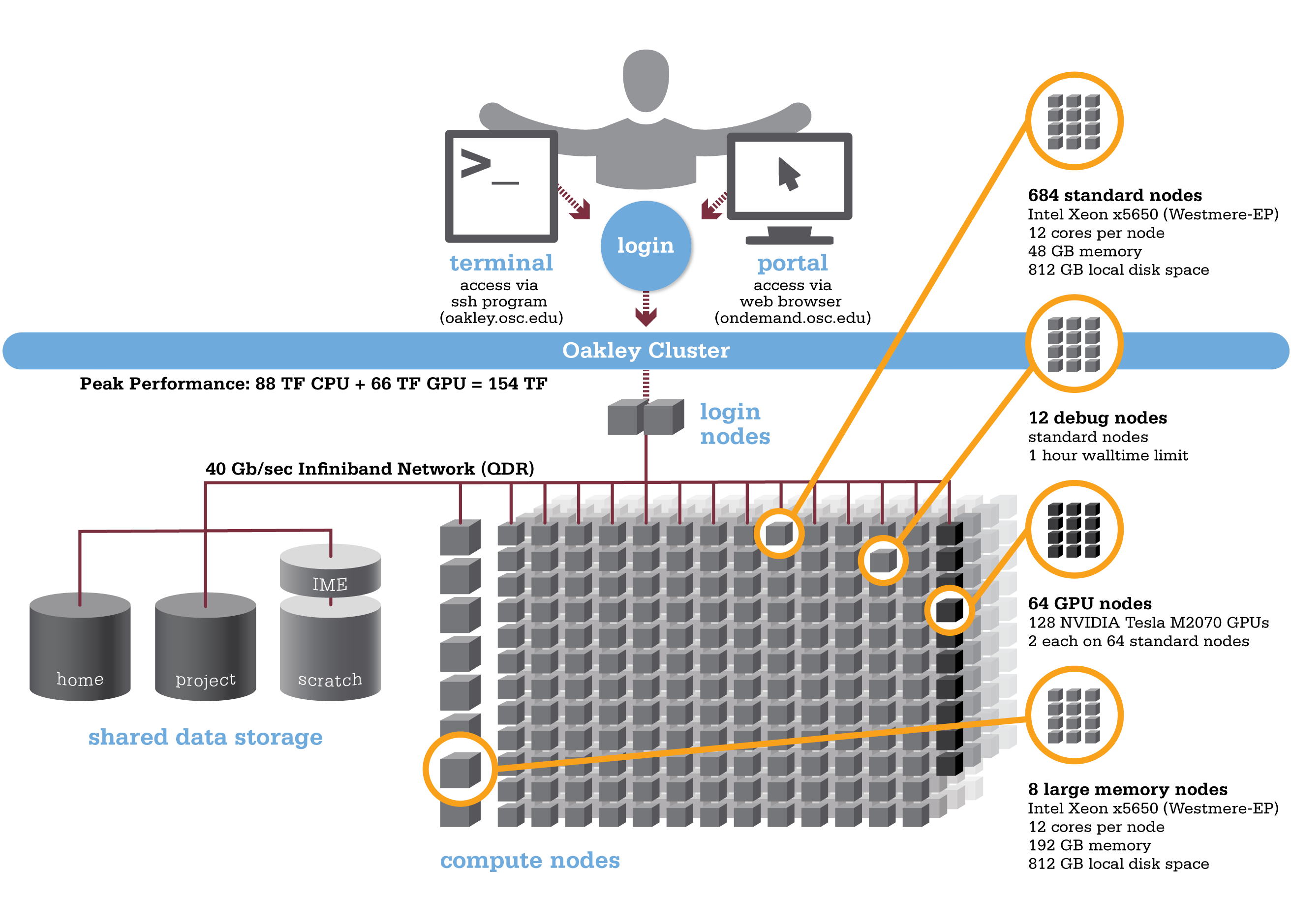
Oakley is an HP-built, Intel® Xeon® processor-based supercomputer, featuring more cores (8,328) on half as many nodes (694) as the center’s former flagship system, the IBM Opteron 1350 Glenn Cluster. The Oakley Cluster can achieve 88 teraflops, tech-speak for performing 88 trillion floating point operations per second, or, with acceleration from 128 NVIDIA® Tesla graphic processing units (GPUs), a total peak performance of just over 154 teraflops.
Hardware
 Detailed system specifications:
Detailed system specifications:
- 8,328 total cores
- Compute Node:
- HP SL390 G7 two-socket servers with Intel Xeon x5650 (Westmere-EP, 6 cores, 2.67GHz) processors
- 12 cores/node & 48 gigabytes of memory/node
- GPU Node:
- 128 NVIDIA Tesla M2070 GPUs
- 873 GB of local disk space in '/tmp'
- QDR IB Interconnect (40Gbps)
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 88.6 teraflops
- GPU acceleration
- Additional 65.5 teraflops
- Total peak performance
- 154.1 teraflops
- Memory Increase
- Increases memory from 2.5 gigabytes per core of Glenn system to 4.0 gigabytes per core.
- System Efficiency
- 1.5x the performance of former Glenn system at just 60 percent of current power consumption.
How to Connect
-
SSH Method
To login to Oakley at OSC, ssh to the following hostname:
oakley.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@oakley.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Oakley login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Oakley at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Oakley Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Oakley are 12 cores/processors per node (ppn). Parallel jobs must use
ppn=12. -
If you need more than 48 GB of RAM per node, you may run on the 8 large memory (192 GB) nodes on Oakley ("bigmem"). You can request a large memory node on Oakley by using the following directive in your batch script:
nodes=XX:ppn=12:bigmem, where XX can be 1-8. - We have a single huge memory node ("hugemem"), with 1 TB of RAM and 32 cores. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node.
nodes=1:ppn=32 with a walltime of 48 hours or less, and the scheduler will put you on the 1 TB node.- GPU jobs may request any number of cores and either 1 or 2 GPUs. Request 2 GPUs per a node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=12:gpus=2
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Technical Specifications
The following are technical specifications for Oakley. We hope these may be of use to the advanced user.
| Oakley System (2012) | |
|---|---|
| Number oF nodes | 670 nodes |
| Number of CPU Cores | 8,328 (12 cores/node) |
| Cores per Node | 12 cores/node |
| Local Disk Space per Node | ~810GB in /tmp, SATA |
| Compute CPU Specifications |
Intel Xeon x5650 (Westmere-EP) CPUs
|
| Computer Server Specifications |
HP SL390 G7 |
|
Accelerator Specifications |
NVIDIA Tesla M2070 |
| Number of accelerator Nodes |
128 GPUs |
| Memory Per Node |
48GB |
| Memory Per Core | 4GB |
| Interconnect |
QDR IB Interconnect
|
| Login Specifications |
2 Intel Xeon x5650
|
| Special Nodes |
Large Memory (8)
Huge Memory (1)
|
Batch Limit Rules
Memory Limit:
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs. On Oakley, it equates to 4GB/core and 48GB/node.
If your job requests less than a full node ( ppn< 12), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (4GB/core). For example, without any memory request ( mem=XX ), a job that requests nodes=1:ppn=1 will be assigned one core and should use no more than 4GB of RAM, a job that requests nodes=1:ppn=3 will be assigned 3 cores and should use no more than 12GB of RAM, and a job that requests nodes=1:ppn=12 will be assigned the whole node (12 cores) with 48GB of RAM. However, a job that requests nodes=1:ppn=1,mem=12GB will be assigned one core but have access to 12GB of RAM, and charged for 3 cores worth of Resource Units (RU). See Charging for memory use for more details.
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 48GB/node and charged for the entire nodes regardless of ppn request. For example, a job that requests nodes=10:ppn=1 will be charged for 10 whole nodes (12 cores/node*10 nodes, which is 120 cores worth of RU). A job that requests large-memory node ( nodes=XX:ppn=12:bigmem, XX can be 1-8) will be allocated the entire large-memory node with 192GB of RAM and charged for the whole node (12 cores worth of RU). A job that requests huge-memory node ( nodes=1:ppn=32 ) will be allocated the entire huge-memory node with 1TB of RAM and charged for the whole node (32 cores worth of RU).
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
GPU Limit:
On Oakley, GPU jobs may request any number of cores and either 1 or 2 GPUs ( nodes=XX:ppn=XX: gpus=1 or gpus=2 ). The memory limit depends on the ppn request and follows the rules in Memory Limit.
Walltime Limit
Here are the queues available on Oakley:
|
NAME |
MAX WALLTIME |
MAX JOB SIZE |
NOTES |
|---|---|---|---|
|
Serial |
168 hours |
1 node |
|
|
Longserial |
336 hours |
1 node |
Restricted access |
|
Parallel |
96 hours |
125 nodes |
|
|
Longparallel |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
48 hours |
1 node |
32 core with 1 TB RAM
|
|
Debug |
1 hour |
12 nodes |
|
Job Limit
An individual user can have up to 256 concurrently running jobs and/or up to 2040 processors/cores in use. All the users in a particular group/project can among them have up to 384 concurrently running jobs and/or up to 2040 processors/cores in use. Jobs submitted in excess of these limits are queued but blocked by the scheduler until other jobs exit and free up resources.
A user may have no more than 1000 jobs submitted to both the parallel and serial job queue separately. Jobs submitted in excess of this limit will be rejected.
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Oakley, please use the following Archival Resource Key:
ark:/19495/hpc0cvqn
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2012. Oakley Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:19495/hpc0cvqn
Here is the citation in BibTeX format:
@misc{Oakley2012,
ark = {ark:/19495/hpc0cvqn},
howpublished = {\url{http://osc.edu/ark:/19495/hpc0cvqn}},
year = {2012},
author = {Ohio Supercomputer Center},
title = {Oakley Supercomputer}
}
And in EndNote format:
%0 Generic %T Oakley Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc0cvqn %U http://osc.edu/ark:/19495/hpc0cvqn %D 2012
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Oakley SSH key fingerprints
These are the public key fingerprints for Oakley:
oakley: ssh_host_key.pub = 01:21:16:c4:cd:43:d3:87:6d:fe:da:d1:ab:20:ba:4a
oakley: ssh_host_rsa_key.pub = eb:83:d9:ca:88:ba:e1:70:c9:a2:12:4b:61:ce:02:72
oakley: ssh_host_dsa_key.pub = ef:4c:f6:cd:83:88:d1:ad:13:50:f2:af:90:33:e9:70
These are the SHA256 hashes:
oakley: ssh_host_key.pub = SHA256:685FBToLX5PCXfUoCkDrxosNg7w6L08lDTVsjLiyLQU
oakley: ssh_host_rsa_key.pub = SHA256:D7HjrL4rsYDGagmihFRqy284kAcscqhthYdzT4w0aUo
oakley: ssh_host_dsa_key.pub = SHA256:XplFCsSu7+RDFC6V/1DGt+XXfBjDLk78DNP0crf341U
Queues and Reservations
Here are the queues available on Oakley. Please note that you will be routed to the appropriate queue based on your walltime and job size request.
| Name | Nodes available | max walltime | max job size | notes |
|---|---|---|---|---|
|
Serial |
Available minus reservations |
168 hours |
1 node |
|
|
Longserial |
Available minus reservations |
336 hours |
1 node |
Restricted access |
|
Parallel |
Available minus reservations |
96 hours |
125 nodes |
|
|
Longparallel |
Available minus reservations |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
1 |
48 hours |
1 node |
"Available minus reservations" means all nodes in the cluster currently operational (this will fluctuate slightly), less the reservations listed below. To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if the performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
In addition, there are a few standing reservations.
| Name | Nodes Available | Max Walltime | Max job size | notes |
|---|---|---|---|---|
| Debug |
12 regualr nodes 4 GPU nodes |
1 hour | 16 nodes | For small interactive and test jobs during 8AM-6PM, Monday - Friday. |
| GPU | 62 | 336 hours | 62 nodes |
Small jobs not requiring GPUs from the serial and parallel queues will backfill on this reservation. |
| OneTB | 1 | 48 hours | 1 node | Holds the 32 core, 1 TB RAM node aside for the hugemem queue. |
Occasionally, reservations will be created for specific projects that will not be reflected in these tables.