Decommissioned Supercomputers
OSC has operated a number of supercomputer systems over the years. Here is a list of previous machines and their specifications.
Ascend (Legacy Documentation)
OSC's Ascend cluster was installed in fall 2022 and is a Dell-built, AMD EPYC™ CPUs with NVIDIA A100 80GB GPUs cluster devoted entirely to intensive GPU processing.
NEW! OSC will be expanding computing resources on the Ascend cluster between late 2024 and early 2025. Please see new specifications below and this announcement about the forthcoming changes.

Hardware

Detailed system specifications:
- 24 Power Edge XE 8545 nodes, each with:
- 2 AMD EPYC 7643 (Milan) processors (2.3 GHz, each with 44 usable cores)
- 4 NVIDIA A100 GPUs with 80GB memory each, supercharged by NVIDIA NVLink
- 921GB usable RAM
- 12.8TB NVMe internal storage
- 2,112 total usable cores
- 88 cores/node & 921GB of memory/node
- Mellanox/NVIDA 200 Gbps HDR InfiniBand
- Theoretical system peak performance
- 1.95 petaflops
- 2 login nodes
- IP address: 192.148.247.[180-181]
Coming soon: Expanded Ascend capabilities (late 2024 to early 2025):
The next-generation system will feature an addition 274 Dell R7525 server nodes each with:
- Two AMD EPYC 7H12 2.60GHz, 64 cores each, 128 cores per server (120 usable)
- Two NVIDIA Ampere A100, PCIe, 250W, 40GB GPUs
- 512GB Memory
- 1.92TB NVMe drive
- HDR100 Infiniband (100 Gbps)
How to Connect
-
SSH Method
To login to Ascend at OSC, ssh to the following hostname:
ascend.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@ascend.osc.edu
You may see a warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprints listed here, then type yes.
From there, you are connected to the Ascend login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Ascend at OSC with our OnDemand tool. The first step is to log into OnDemand. Then once logged in you can access Ascend by clicking on "Clusters", and then selecting ">_Ascend Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
File Systems
Ascend accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the old clusters. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system on Ascend is the same as on the Owens and Pitzer systems. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider .
You can keep up to the software packages that have been made available on Ascend by viewing the Software by System page and selecting the Ascend system.
Batch Specifics
Refer to this Slurm migration page to understand how to use Slurm on the Ascend cluster.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Ascend Programming Environment
Compilers
C, C++ and Fortran are supported on the Ascend cluster. Intel, oneAPI, GNU Compiler Collectio (GCC) and AOCC are available. The Intel development tool chain is loaded by default. Compiler commands and recommended options for serial programs are listed in the table below. See also our compilation guide.
The Rome/Milan processors from AMD that make up Ascend support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use. However, bear in mind that clock speeds decrease as the level of the instruction set increases. So, if your code does not benefit from vectorization it may be beneficial to use a lower instruction set.
In our experience, the Intel compiler usually does the best job of optimizing numerical codes and we recommend that you give it a try if you’ve been using another compiler.
With the Intel/oneAPI compilers, use -xHost and -O2 or higher. With GCC, use -march=native and -O3.
This advice assumes that you are building and running your code on Ascend. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
| LANGUAGE | INTEL | GCC | ONEAPI |
|---|---|---|---|
| C | icc -O2 -xHost hello.c | gcc -O3 -march=native hello.c | icx -O2 -xHost hello.c |
| Fortran | ifort -O2 -xHost hello.F | gfortran -O3 -march=native hello.F | ifx -O2 -xHost hello.F |
| C++ | icpc -O2 -xHost hello.cpp | g++ -O3 -march=native hello.cpp | icpx -O2 -xHost hello.cpp |
Parallel Programming
MPI
By default, OSC systems use the MVAPICH implementation of the Message Passing Interface (MPI), which is optimized for high-speed InfiniBand interconnects. MPI is a standardized library designed for parallel processing in distributed-memory environments. OSC also supports OpenMPI and Intel MPI. For more information on building MPI applications, please visit the MPI software page.
MPI programs are started with the srun command. For example,
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=48
srun [ options ] mpi_prog
The srun command will normally spawn one MPI process per task requested in a Slurm batch job. Use the --ntasks-per-node=n option to change that behavior. For example,
#!/bin/bash #SBATCH --nodes=2 #SBATCh --exclusive # Use the maximum number of CPUs of two nodes srun ./mpi_prog # Run 8 processes per node srun -n 16 --ntasks-per-node=8 ./mpi_prog
The table below shows some commonly used options. Use srun -help for more information.
| OPTION | COMMENT |
|---|---|
--ntasks-per-node=n |
number of tasks to invoke on each node |
-help |
Get a list of available options |
srun in any circumstances.OpenMP
The Intel, and GNU compilers understand the OpenMP set of directives, which support multithreaded programming. For more information on building OpenMP codes on OSC systems, please visit the OpenMP documentation.
An OpenMP program by default will use a number of threads equal to the number of CPUs requested in a Slurm batch job. To use a different number of threads, set the environment variable OMP_NUM_THREADS. For example,
#!/bin/bash #SBATCH --nodes=1 #SBATCH --ntasks-per-node=8 # Run 8 threads ./omp_prog # Run 4 threads export OMP_NUM_THREADS=4 ./omp_prog
Interactive job only
Please use -c, --cpus-per-task=X to request an interactive job. Both result in an interactive job with X CPUs available but only the former option automatically assigns the correct number of threads to the OpenMP program.
Hybrid (MPI + OpenMP)
An example of running a job for hybrid code:
#!/bin/bash #SBATCH --nodes=2 #SBATCH --ntasks-per-node=80 # Run 4 MPI processes on each node and 40 OpenMP threads spawned from a MPI process export OMP_NUM_THREADS=40 srun -n 8 -c 40 --ntasks-per-node=4 ./hybrid_prog
Tuning Parallel Program Performance: Process/Thread Placement
To get the maximum performance, it is important to make sure that processes/threads are located as close as possible to their data, and as close as possible to each other if they need to work on the same piece of data, with given the arrangement of node, sockets, and cores, with different access to RAM and caches.
While cache and memory contention between threads/processes are an issue, it is best to use scatter distribution for code.
Processes and threads are placed differently depending on the computing resources you requste and the compiler and MPI implementation used to compile your code. For the former, see the above examples to learn how to run a job on exclusive nodes. For the latter, this section summarizes the default behavior and how to modify placement.
OpenMP only
For all three compilers (Intel, GCC and oneAPI), purely threaded codes do not bind to particular CPU cores by default. In other words, it is possible that multiple threads are bound to the same CPU core.
The following table describes how to modify the default placements for pure threaded code:
| DISTRIBUTION | Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place threads close to each other as possible in successive order | Distribute threads as evenly as possible across sockets |
| INTEL/ONEAPI | KMP_AFFINITY=compact | KMP_AFFINITY=scatter |
| GCC | OMP_PLACES=sockets[1] | OMP_PROC_BIND=true OMP_PLACES=cores |
- Threads in the same socket might be bound to the same CPU core.
MPI Only
For MPI-only codes, MVAPICH first binds as many processes as possible on one socket, then allocates the remaining processes on the second socket so that consecutive tasks are near each other. Intel MPI and OpenMPI alternately bind processes on socket 1, socket 2, socket 1, socket 2 etc, as cyclic distribution.
For process distribution across nodes, all MPIs first bind as many processes as possible on one node, then allocates the remaining processes on the second node.
The following table describe how to modify the default placements on single node for MPI-only code with the command srun:
| DISTRIBUTION (single node) |
Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place processs close to each other as possible in successive order | Distribute process as evenly as possible across sockets |
| MVAPICH[1] | Default | MVP_CPU_BINDING_POLICY=scatter |
| INTEL MPI | SLURM_DISTRIBUTION=block:block srun -B "2:*:1" ./mpi_prog |
SLURM_DISTRIBUTION=block:cyclic srun -B "2:*:1" ./mpi_prog |
| OPENMPI | SLURM_DISTRIBUTION=block:block srun -B "2:*:1" ./mpi_prog |
SLURM_DISTRIBUTION=block:cyclic srun -B "2:*:1" ./mpi_prog |
MVP_CPU_BINDING_POLICYwill not work ifMVP_ENABLE_AFFINITY=0is set.
To distribute processes evenly across nodes, please set SLURM_DISTRIBUTION=cyclic.
Hybrid (MPI + OpenMP)
For hybrid codes, each MPI process is allocated a number of cores defined by OMP_NUM_THREADS, and the threads of each process are bound to those cores. All MPI processes, along with the threads bound to them, behave similarly to what was described in the previous sections.
The following table describe how to modify the default placements on a single node for Hybrid code with the command srun:
| DISTRIBUTION (single node) |
Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place processs as closely as possible on sockets | Distribute process as evenly as possible across sockets |
| MVAPICH[1] | Default | MVP_HYBRID_BINDING_POLICY=scatter |
| INTEL MPI[2] | SLURM_DISTRIBUTION=block:block | SLURM_DISTRIBUTION=block:cyclic |
| OPENMPI[2] | SLURM_DISTRIBUTION=block:block | SLURM_DISTRIBUTION=block:cyclic |
Summary
The above tables list the most commonly used settings for process/thread placement. Some compilers and Intel libraries may have additional options for process and thread placement beyond those mentioned on this page. For more information on a specific compiler/library, check the more detailed documentation for that library.
GPU Programming
244 NVIDIA A100 GPUs are available on Ascend. Please visit our GPU documentation.
Reference
Batch Limit Rules
Memory limit
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs.
Summary
| Node type | default memory per core (GB) | max usable memory per node (GB) |
|---|---|---|
| gpu (4 gpus) - 88 cores | 10.4726 GB | 921.5937 GB |
It is recommended to let the default memory apply unless more control over memory is needed.
Note that if an entire node is requested, then the job is automatically granted the entire node's main memory. On the other hand, if a partial node is requested, then memory is granted based on the default memory per core.
See a more detailed explanation below.
Default memory limits
A job can request resources and allow the default memory to apply. If a job requires 300 GB for example:
#SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=30
This requests 30 cores, and each core will automatically be allocated 10.4 GB of memory (30 core * 10 GB memory = 300 GB memory).
Explicit memory requests
If needed, an explicit memory request can be added:
#SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=4 #SBATCH --mem=300G
See Job and storage charging for details.
CPU only jobs
Dense gpu nodes on Ascend have 88 cores each. However, cpuonly partition jobs may only request 84 cores per node.
An example request would look like:
#!/bin/bash #SBATCH --partition=cpuonly #SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks-per-node=2 #SBATCH --cpus-per-task=42 # requests 2 tasks * 42 cores each = 84 cores <snip>
GPU Jobs
Jobs may request only parts of gpu node. These jobs may request up to the total cores on the node (88 cores).
Requests two gpus for one task:
#SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=20 #SBATCH --gpus-per-task=2
Requests two gpus, one for each task:
#SBATCH --time=5:00:00 #SBATCH --nodes=1 #SBATCH --ntasks-per-node=2 #SBATCH --cpus-per-task=10 #SBATCH --gpus-per-task=1
Of course, jobs can request all the gpus of a dense gpu node as well. These jobs have access to all cores as well.
Request an entire dense gpu node:
#SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=88 #SBATCH --gpus-per-node=4
Partition time and job size limits
Here is the walltime and node limits per job for different queues/partitions available on Ascend:
|
NAME |
MAX TIME LIMIT |
MIN JOB SIZE |
MAX JOB SIZE |
NOTES |
|---|---|---|---|---|
|
cpuonly |
4-00:00:00 |
1 core |
4 nodes |
This partition may not request gpus 84 cores per node only |
| gpu |
7-00:00:00 |
1 core |
4 nodes |
|
| debug | 1:00:00 | 1 core | 2 nodes | |
| preemptible | 1-00:00:00 | 1 core | 4 nodes | The job in this partition will be terminated when there are pending job with higher priority; you need to specify this explicitly |
Usually, you do not need to specify the partition for a job and the scheduler will assign the right partition based on the requested resources. To specify a partition for a job, either add the flag --partition=<partition-name> to the sbatch command at submission time or add this line to the job script:
#SBATCH --paritition=<partition-name>
Job/Core Limits
| Max Running Job Limit | Max Core/Processor Limit | Max GPU limit | ||
|---|---|---|---|---|
| For all types | GPU debug jobs | For all types | ||
| Individual User | 256 | 4 |
704 |
32 |
| Project/Group | 512 | n/a | 704 | 32 |
An individual user can have up to the max concurrently running jobs and/or up to the max processors/cores in use. However, among all the users in a particular group/project, they can have up to the max concurrently running jobs and/or up to the max processors/cores in use.
Migrating jobs from other clusters
This page includes a summary of differences to keep in mind when migrating jobs from other clusters to Ascend.
Guidance for Pitzer Users
Hardware Specifications
| Ascend (PER NODE) | Pitzer (PER NODE) | ||
|---|---|---|---|
| Regular compute node | n/a |
40 cores and 192GB of RAM 48 cores and 192GB of RAM |
|
| Huge memory node |
n/a |
48 cores and 768GB of RAM (12 nodes in this class) 80 cores and 3.0 TB of RAM (4 nodes in this class) |
|
| GPU Node |
88 cores and 921GB RAM 4 GPUs per node (24 nodes in this class) |
40 cores and 192GB of RAM, 2 GPUs per node (32 nodes in this class) 48 cores and 192GB of RAM, 2 GPUs per node (42 nodes in this class) |
|
Guidance for Owens Users
Hardware Specifications
| Ascend (PER NODE) | Owens (PER NODE) | ||
|---|---|---|---|
| Regular compute node | n/a | 28 cores and 125GB of RAM | |
| Huge memory node | n/a |
48 cores and 1.5TB of RAM (16 nodes in this class) |
|
| GPU node |
88 cores and 921GB RAM 4 GPUs per node (24 nodes in this class) |
28 cores and 125GB of RAM, 1 GPU per node (160 nodes in this class) |
|
File Systems
Ascend accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory, project space, and scratch space as on the other clusters.
Software Environment
Ascend uses the same module system as other OSC Clusters.
Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider .
You can keep up to on the software packages that have been made available on Ascend by viewing the Software by System page and selecting the Ascend system.
Programming Environment
C, C++ and Fortran are supported on the Ascend cluster. Intel, oneAPI, GNU, nvhpc, and aocc compiler suites are available. The Intel development tool chain is loaded by default. To switch to a different compiler, use module swap . Ascend also uses the MVAPICH2 implementation of the Message Passing Interface (MPI).
See the Ascend Programming Environment page for details.
Ascend SSH key fingerprints
These are the public key fingerprints for Ascend:
ascend: ssh_host_rsa_key.pub = 2f:ad:ee:99:5a:f4:7f:0d:58:8f:d1:70:9d:e4:f4:16
ascend: ssh_host_ed25519_key.pub = 6b:0e:f1:fb:10:da:8c:0b:36:12:04:57:2b:2c:2b:4d
ascend: ssh_host_ecdsa_key.pub = f4:6f:b5:d2:fa:96:02:73:9a:40:5e:cf:ad:6d:19:e5
These are the SHA256 hashes:
ascend: ssh_host_rsa_key.pub = SHA256:4l25PJOI9sDUaz9NjUJ9z/GIiw0QV/h86DOoudzk4oQ
ascend: ssh_host_ed25519_key.pub = SHA256:pvz/XrtS+PPv4nsn6G10Nfc7yM7CtWoTnkgQwz+WmNY
ascend: ssh_host_ecdsa_key.pub = SHA256:giMUelxDSD8BTWwyECO10SCohi3ahLPBtkL2qJ3l080
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Ascend, please use the following Archival Resource Key:
ark:/19495/hpc3ww9d
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2022. Ascend Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:/19495/hpc3ww9d
Here is the citation in BibTeX format:
@misc{Ascend2022,
ark = {ark:/19495/hpc3ww9d},
url = {http://osc.edu/ark:/19495/hpc3ww9d},
year = {2022},
author = {Ohio Supercomputer Center},
title = {Ascend Supercomputer}
}
And in EndNote format:
%0 Generic %T Ascend Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc3ww9d %U http://osc.edu/ark:/19495/hpc3ww9d %D 2022
Request access
Users who would like to use the Ascend cluster will need to request access. This is because of the particulars of the Ascend environment, which includes its size, GPUs, and scheduling policies.
Motivation
Access to Ascend is done on a case by case basis because:
- All nodes on Ascend are with 4 GPUs, and therefore it favors GPU work instead of CPU-only work
- It is a smaller machine than Pitzer and Owens, and thus has limited space for users
Good Ascend Workload Characteristics
Those interested in using Ascend should check that their work is well suited for it by using the following list. Ideal workloads will exhibit one or more of the following characteristics:
- Needs access to Ascend specific hardware (GPUs, or AMD)
- Software:
- Supports GPUs
- Takes advantage of:
- Long vector length
- Higher core count
- Improved memory bandwidth
Applying for Access
PIs of groups that would like to be considered for Ascend access should send the following in a email to OSC Help:
- Name
- Username
- Project code (group)
- Software/packages used on Ascend
- Evidence of workload being well suited for Ascend
Technical Specifications
The following are technical specifications for Ascend.
- Number of Nodes
-
24 nodes
- Number of CPU Sockets
-
48 (2 sockets/node)
- Number of CPU Cores
-
2,304 (96 cores/node)
- Cores Per Node
-
96 cores/node (88 usable cores/node)
- Internal Storage
-
12.8 TB NVMe internal storage
- Compute CPU Specifications
-
AMD EPYC 7643 (Milan) processors for compute
- 2.3 GHz
- 48 cores per processor
- Computer Server Specifications
-
24 Dell XE8545 servers
- Accelerator Specifications
-
4 NVIDIA A100 GPUs with 80GB memory each, supercharged by NVIDIA NVLink
- Number of Accelerator Nodes
-
24 total
- Total Memory
- ~ 24 TB
- Physical Memory Per Node
-
1 TB
- Physical Memory Per Core
-
10.6 GB
- Interconnect
-
Mellanox/NVIDA 200 Gbps HDR InfiniBand
Ruby
Ruby was named after the Ohio native actress Ruby Dee. An HP built, Intel® Xeon® processor-based supercomputer, Ruby provided almost the same amount of total computing power (~125 TF, used to be ~144 TF with Intel® Xeon® Phi coprocessors) as our former flagship system Oakley on less than half the number of nodes (240 nodes). Ruby had has 20 nodes are outfitted with NVIDIA® Tesla K40 accelerators (Ruby used to feature two distinct sets of hardware accelerators; 20 nodes were outfitted with NVIDIA® Tesla K40 and another 20 nodes feature Intel® Xeon® Phi coprocessors).
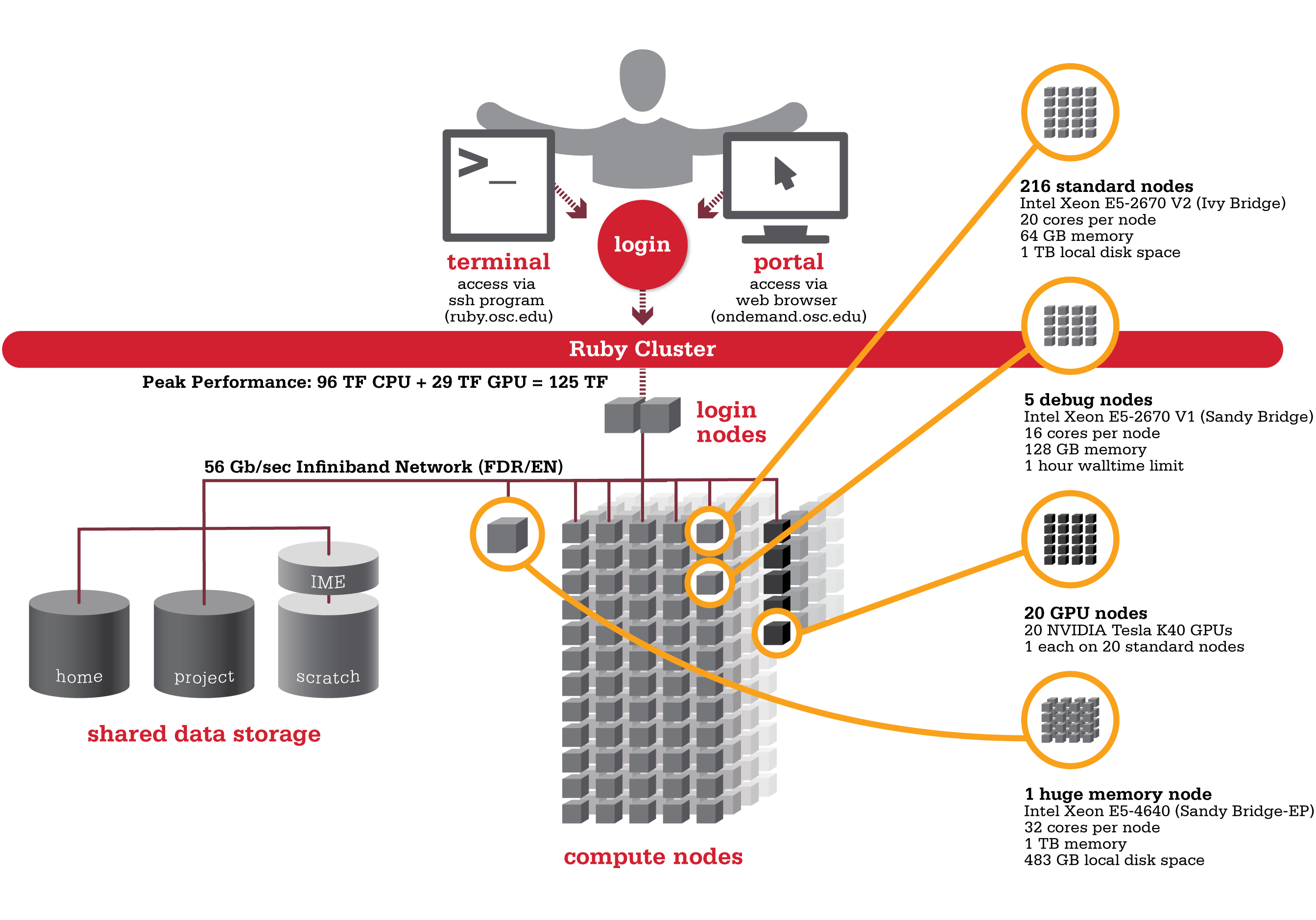
![]() Hardware
Hardware
Detailed system specifications:
- 4800 total cores
- 20 cores/node & 64 gigabytes of memory/node
- Intel Xeon E5 2670 V2 (Ivy Bridge) CPUs
- HP SL250 Nodes
20 Intel Xeon Phi 5110p coprocessors(remove from service on 10/13/2016)- 20 NVIDIA Tesla K40 GPUs
- 2 NVIDIA Tesla K80 GPUs
- Both equipped on single "debug" queue node
- 850 GB of local disk space in '/tmp'
- FDR IB Interconnect
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 96 teraflops
- NVIDIA GPU performance
- 28.6 additional teraflops
Intel Xeon Phi performance20 additional teraflops
- Total peak performance
- ~125 teraflops
Ruby has one huge memory node.
- 32 cores (Intel Xeon E5 4640 CPUs)
- 1 TB of memory
- 483 GB of local disk space in '/tmp'
Ruby is configured with two login nodes.
- Intel Xeon E5-2670 (Sandy Bridge) CPUs
- 16 cores/node & 128 gigabytes of memory/node
How to Connect
-
SSH Method
To login to Ruby at OSC, ssh to the following hostname:
ruby.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@ruby.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Ruby login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Ruby at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Ruby Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
File Systems
Ruby accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the Oakley Cluster. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system on Ruby is the same as on the Oakley system. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the module that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider . By default, you will have the batch scheduling software modules, the Intel compiler and an appropriate version of mvapich2 loaded.
You can keep up to on the software packages that have been made available on Ruby by viewing the Software by System page and selecting the Ruby system.
Understanding the Xeon Phi
Guidance on what the Phis are, how they can be utilized, and other general information can be found on our Ruby Phi FAQ.
Compiling for the Xeon Phis
For information on compiling for and running software on our Phi coprocessors, see our Phi Compiling Guide.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Ruby have 20 cores/processors per node (ppn).
- If you need more than 64 GB of RAM per node you may run on Ruby's huge memory node ("hugemem"). This node has four Intel Xeon E5-4640 CPUs (8 cores/CPU) for a total of 32 cores. The node also has 1TB of RAM. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node. - 20 nodes on Ruby are equipped with a single NVIDIA Tesla K40 GPUs. These nodes can be requested by adding
gpus=1to your nodes request, like so:#PBS -l nodes=1:ppn=20:gpus=1.- By default a GPU is set to the Exclusive Process and Thread compute mode at the beginning of each job. To request the GPU be set to Default compute mode, add
defaultto your nodes request, like so:#PBS -l nodes=1:ppn=20:gpus=1:default.
- By default a GPU is set to the Exclusive Process and Thread compute mode at the beginning of each job. To request the GPU be set to Default compute mode, add
- Ruby has 4 debug nodes (2 non-GPU nodes, as well as 2 GPU nodes, with 2 GPUs per node), which are specifically configured for short (< 1 hour) debugging type work. These nodes have a walltime limit of 1 hour. These nodes are equipped with E5-2670 V1 CPUs with 16 cores per a node.
- To schedule a non-GPU debug node:
#PBS -l nodes=1:ppn=16 -q debug
- To schedule a GPU debug node:
#PBS -l nodes=1:ppn=16:gpus=2 -q debug
- To schedule a non-GPU debug node:
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Oakley
Oakley is an HP-built, Intel® Xeon® processor-based supercomputer, featuring more cores (8,328) on half as many nodes (694) as the center’s former flagship system, the IBM Opteron 1350 Glenn Cluster. The Oakley Cluster can achieve 88 teraflops, tech-speak for performing 88 trillion floating point operations per second, or, with acceleration from 128 NVIDIA® Tesla graphic processing units (GPUs), a total peak performance of just over 154 teraflops.
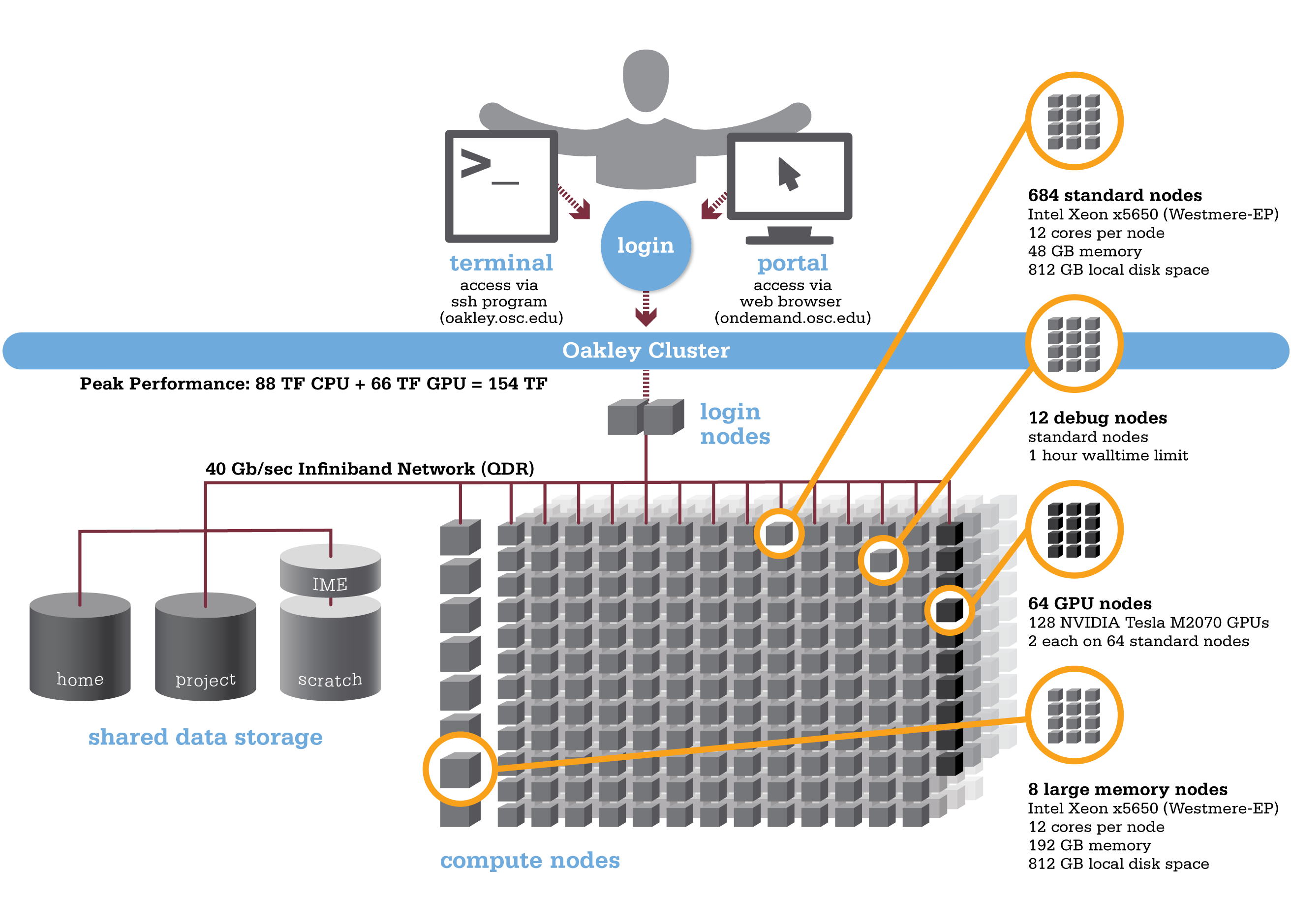
Hardware
 Detailed system specifications:
Detailed system specifications:
- 8,328 total cores
- Compute Node:
- HP SL390 G7 two-socket servers with Intel Xeon x5650 (Westmere-EP, 6 cores, 2.67GHz) processors
- 12 cores/node & 48 gigabytes of memory/node
- GPU Node:
- 128 NVIDIA Tesla M2070 GPUs
- 873 GB of local disk space in '/tmp'
- QDR IB Interconnect (40Gbps)
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 88.6 teraflops
- GPU acceleration
- Additional 65.5 teraflops
- Total peak performance
- 154.1 teraflops
- Memory Increase
- Increases memory from 2.5 gigabytes per core of Glenn system to 4.0 gigabytes per core.
- System Efficiency
- 1.5x the performance of former Glenn system at just 60 percent of current power consumption.
How to Connect
-
SSH Method
To login to Oakley at OSC, ssh to the following hostname:
oakley.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@oakley.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Oakley login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Oakley at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Oakley Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Oakley are 12 cores/processors per node (ppn). Parallel jobs must use
ppn=12. -
If you need more than 48 GB of RAM per node, you may run on the 8 large memory (192 GB) nodes on Oakley ("bigmem"). You can request a large memory node on Oakley by using the following directive in your batch script:
nodes=XX:ppn=12:bigmem, where XX can be 1-8. - We have a single huge memory node ("hugemem"), with 1 TB of RAM and 32 cores. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node.
nodes=1:ppn=32 with a walltime of 48 hours or less, and the scheduler will put you on the 1 TB node.- GPU jobs may request any number of cores and either 1 or 2 GPUs. Request 2 GPUs per a node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=12:gpus=2
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Technical Specifications
The following are technical specifications for Oakley. We hope these may be of use to the advanced user.
| Oakley System (2012) | |
|---|---|
| Number oF nodes | 670 nodes |
| Number of CPU Cores | 8,328 (12 cores/node) |
| Cores per Node | 12 cores/node |
| Local Disk Space per Node | ~810GB in /tmp, SATA |
| Compute CPU Specifications |
Intel Xeon x5650 (Westmere-EP) CPUs
|
| Computer Server Specifications |
HP SL390 G7 |
|
Accelerator Specifications |
NVIDIA Tesla M2070 |
| Number of accelerator Nodes |
128 GPUs |
| Memory Per Node |
48GB |
| Memory Per Core | 4GB |
| Interconnect |
QDR IB Interconnect
|
| Login Specifications |
2 Intel Xeon x5650
|
| Special Nodes |
Large Memory (8)
Huge Memory (1)
|
Batch Limit Rules
Memory Limit:
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs. On Oakley, it equates to 4GB/core and 48GB/node.
If your job requests less than a full node ( ppn< 12), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (4GB/core). For example, without any memory request ( mem=XX ), a job that requests nodes=1:ppn=1 will be assigned one core and should use no more than 4GB of RAM, a job that requests nodes=1:ppn=3 will be assigned 3 cores and should use no more than 12GB of RAM, and a job that requests nodes=1:ppn=12 will be assigned the whole node (12 cores) with 48GB of RAM. However, a job that requests nodes=1:ppn=1,mem=12GB will be assigned one core but have access to 12GB of RAM, and charged for 3 cores worth of Resource Units (RU). See Charging for memory use for more details.
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 48GB/node and charged for the entire nodes regardless of ppn request. For example, a job that requests nodes=10:ppn=1 will be charged for 10 whole nodes (12 cores/node*10 nodes, which is 120 cores worth of RU). A job that requests large-memory node ( nodes=XX:ppn=12:bigmem, XX can be 1-8) will be allocated the entire large-memory node with 192GB of RAM and charged for the whole node (12 cores worth of RU). A job that requests huge-memory node ( nodes=1:ppn=32 ) will be allocated the entire huge-memory node with 1TB of RAM and charged for the whole node (32 cores worth of RU).
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
GPU Limit:
On Oakley, GPU jobs may request any number of cores and either 1 or 2 GPUs ( nodes=XX:ppn=XX: gpus=1 or gpus=2 ). The memory limit depends on the ppn request and follows the rules in Memory Limit.
Walltime Limit
Here are the queues available on Oakley:
|
NAME |
MAX WALLTIME |
MAX JOB SIZE |
NOTES |
|---|---|---|---|
|
Serial |
168 hours |
1 node |
|
|
Longserial |
336 hours |
1 node |
Restricted access |
|
Parallel |
96 hours |
125 nodes |
|
|
Longparallel |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
48 hours |
1 node |
32 core with 1 TB RAM
|
|
Debug |
1 hour |
12 nodes |
|
Job Limit
An individual user can have up to 256 concurrently running jobs and/or up to 2040 processors/cores in use. All the users in a particular group/project can among them have up to 384 concurrently running jobs and/or up to 2040 processors/cores in use. Jobs submitted in excess of these limits are queued but blocked by the scheduler until other jobs exit and free up resources.
A user may have no more than 1000 jobs submitted to both the parallel and serial job queue separately. Jobs submitted in excess of this limit will be rejected.
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Oakley, please use the following Archival Resource Key:
ark:/19495/hpc0cvqn
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2012. Oakley Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:19495/hpc0cvqn
Here is the citation in BibTeX format:
@misc{Oakley2012,
ark = {ark:/19495/hpc0cvqn},
howpublished = {\url{http://osc.edu/ark:/19495/hpc0cvqn}},
year = {2012},
author = {Ohio Supercomputer Center},
title = {Oakley Supercomputer}
}
And in EndNote format:
%0 Generic %T Oakley Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc0cvqn %U http://osc.edu/ark:/19495/hpc0cvqn %D 2012
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Oakley SSH key fingerprints
These are the public key fingerprints for Oakley:
oakley: ssh_host_key.pub = 01:21:16:c4:cd:43:d3:87:6d:fe:da:d1:ab:20:ba:4a
oakley: ssh_host_rsa_key.pub = eb:83:d9:ca:88:ba:e1:70:c9:a2:12:4b:61:ce:02:72
oakley: ssh_host_dsa_key.pub = ef:4c:f6:cd:83:88:d1:ad:13:50:f2:af:90:33:e9:70
These are the SHA256 hashes:
oakley: ssh_host_key.pub = SHA256:685FBToLX5PCXfUoCkDrxosNg7w6L08lDTVsjLiyLQU
oakley: ssh_host_rsa_key.pub = SHA256:D7HjrL4rsYDGagmihFRqy284kAcscqhthYdzT4w0aUo
oakley: ssh_host_dsa_key.pub = SHA256:XplFCsSu7+RDFC6V/1DGt+XXfBjDLk78DNP0crf341U
Queues and Reservations
Here are the queues available on Oakley. Please note that you will be routed to the appropriate queue based on your walltime and job size request.
| Name | Nodes available | max walltime | max job size | notes |
|---|---|---|---|---|
|
Serial |
Available minus reservations |
168 hours |
1 node |
|
|
Longserial |
Available minus reservations |
336 hours |
1 node |
Restricted access |
|
Parallel |
Available minus reservations |
96 hours |
125 nodes |
|
|
Longparallel |
Available minus reservations |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
1 |
48 hours |
1 node |
"Available minus reservations" means all nodes in the cluster currently operational (this will fluctuate slightly), less the reservations listed below. To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if the performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
In addition, there are a few standing reservations.
| Name | Nodes Available | Max Walltime | Max job size | notes |
|---|---|---|---|---|
| Debug |
12 regualr nodes 4 GPU nodes |
1 hour | 16 nodes | For small interactive and test jobs during 8AM-6PM, Monday - Friday. |
| GPU | 62 | 336 hours | 62 nodes |
Small jobs not requiring GPUs from the serial and parallel queues will backfill on this reservation. |
| OneTB | 1 | 48 hours | 1 node | Holds the 32 core, 1 TB RAM node aside for the hugemem queue. |
Occasionally, reservations will be created for specific projects that will not be reflected in these tables.
Owens
OSC's Owens cluster being installed in 2016 is a Dell-built, Intel® Xeon® processor-based supercomputer.
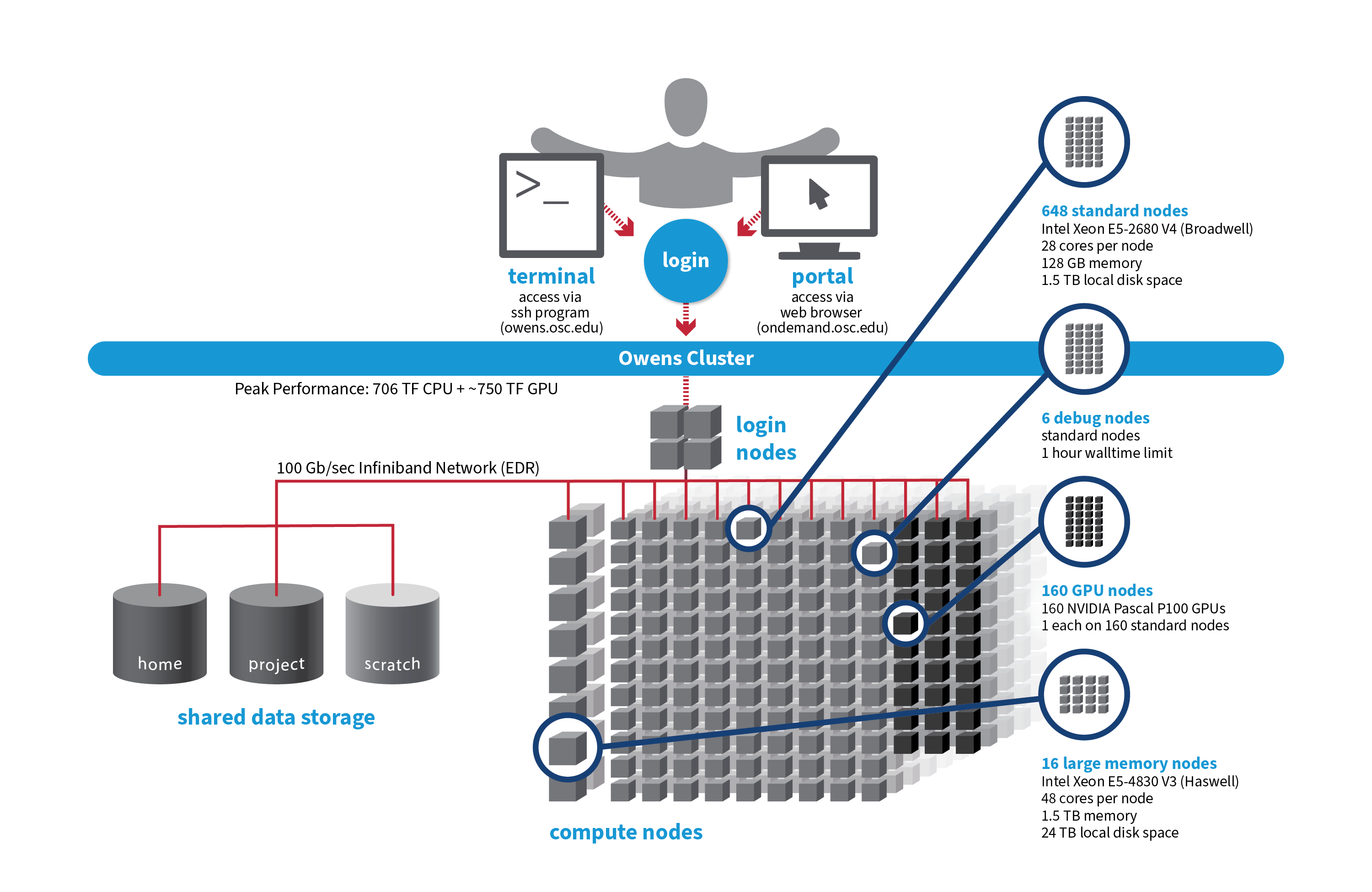
Hardware

Detailed system specifications:
Please see owens batch limits for details on user available memory amount.
- 824 Dell Nodes
- Dense Compute
-
648 compute nodes (Dell PowerEdge C6320 two-socket servers with Intel Xeon E5-2680 v4 (Broadwell, 14 cores, 2.40 GHz) processors, 128 GB memory)
-
-
GPU Compute
-
160 ‘GPU ready’ compute nodes -- Dell PowerEdge R730 two-socket servers with Intel Xeon E5-2680 v4 (Broadwell, 14 cores, 2.40 GHz) processors, 128 GB memory
-
NVIDIA Tesla P100 (Pascal) GPUs -- 5.3 TF peak (double precision), 16 GB memory
-
-
Analytics
-
16 huge memory nodes (Dell PowerEdge R930 four-socket server with Intel Xeon E5-4830 v3 (Haswell 12 core, 2.10 GHz) processors, 1,536 GB memory, 12 x 2 TB drives)
-
- 23,392 total cores
- 28 cores/node & 128 GB of memory/node
- Mellanox EDR (100 Gbps) Infiniband networking
- Theoretical system peak performance
- ~750 teraflops (CPU only)
- 4 login nodes:
- Intel Xeon E5-2680 (Broadwell) CPUs
- 28 cores/node and 256 GB of memory/node
- IP address: 192.148.247.[141-144]
How to Connect
-
SSH Method
To login to Owens at OSC, ssh to the following hostname:
owens.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@owens.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Owens login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Owens at OSC with our OnDemand tool. The first step is to login to OnDemand. Then once logged in you can access Owens by clicking on "Clusters", and then selecting ">_Owens Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documention page.
File Systems
Owens accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the old clusters. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system is used to manage the software environment on owens. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider . By default, you will have the batch scheduling software modules, the Intel compiler and an appropriate version of mvapich2 loaded.
You can keep up to on the software packages that have been made available on Owens by viewing the Software by System page and selecting the Owens system.
Compiling Code to Use Advanced Vector Extensions (AVX2)
The Haswell and Broadwell processors that make up Owens support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use.
In our experience, the Intel and PGI compilers do a much better job than the gnu compilers at optimizing HPC code.
With the Intel compilers, use -xHost and -O2 or higher. With the gnu compilers, use -march=native and -O3 . The PGI compilers by default use the highest available instruction set, so no additional flags are necessary.
This advice assumes that you are building and running your code on Owens. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
See the Owens Programming Environment page for details.
Batch Specifics
Refer to the documentation for our batch environment to understand how to use the batch system on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Most compute nodes on Owens have 28 cores/processors per node. Huge-memory (analytics) nodes have 48 cores/processors per node.
- Jobs on Owens may request partial nodes.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Technical Specifications
The following are technical specifications for Owens.
- Number of Nodes
-
824 nodes
- Number of CPU Sockets
-
1,648 (2 sockets/node)
- Number of CPU Cores
-
23,392 (28 cores/node)
- Cores Per Node
-
28 cores/node (48 cores/node for Huge Mem Nodes)
- Local Disk Space Per Node
-
~1,500GB in /tmp
- Compute CPU Specifications
-
Intel Xeon E5-2680 v4 (Broadwell) for compute
- 2.4 GHz
- 14 cores per processor
- Computer Server Specifications
-
- 648 Dell PowerEdge C6320
- 160 Dell PowerEdge R730 (for accelerator nodes)
- Accelerator Specifications
-
NVIDIA P100 "Pascal" GPUs 16GB memory
- Number of Accelerator Nodes
-
160 total
- Total Memory
- ~ 127 TB
- Memory Per Node
-
128 GB (1.5 TB for Huge Mem Nodes)
- Memory Per Core
-
4.5 GB (31 GB for Huge Mem)
- Interconnect
-
Mellanox EDR Infiniband Networking (100Gbps)
- Login Specifications
-
4 Intel Xeon E5-2680 (Broadwell) CPUs
- 28 cores/node and 256GB of memory/node
- Special Nodes
-
16 Huge Memory Nodes
- Dell PowerEdge R930
- 4 Intel Xeon E5-4830 v3 (Haswell)
- 12 Cores
- 2.1 GHz
- 48 cores (12 cores/CPU)
- 1.5 TB Memory
- 12 x 2 TB Drive (20TB usable)
Environment changes in Slurm migration
As we migrate to Slurm from Torque/Moab, there will be necessary software environment changes.
Decommissioning old MVAPICH2 versions
Old MVAPICH2 including mvapich2/2.1, mvapich2/2.2 and its variants do not support Slurm very well due to its life span, so we will remove the following versions:
- mvapich2/2.1
- mvapich2/2.2, 2.2rc1, 2.2ddn1.3, 2.2ddn1.4, 2.2-debug, 2.2-gpu
As a result, the following dependent software will not be available anymore.
| Unavailable Software | Possible replacement |
|---|---|
| amber/16 | amber/18 |
| darshan/3.1.4 | darshan/3.1.6 |
| darshan/3.1.5-pre1 | darshan/3.1.6 |
| expresso/5.2.1 | expresso/6.3 |
| expresso/6.1 | expresso/6.3 |
| expresso/6.1.2 | expresso/6.3 |
| fftw3/3.3.4 | fftw3/3.3.5 |
| gamess/18Aug2016R1 | gamess/30Sep2019R2 |
| gromacs/2016.4 | gromacs/2018.2 |
| gromacs/5.1.2 | gromacs/2018.2 |
| lammps/14May16 | lammps/16Mar18 |
| lammps/31Mar17 | lammps/16Mar18 |
| mumps/5.0.2 | N/A (no current users) |
| namd/2.11 | namd/2.13 |
| nwchem/6.6 | nwchem/6.8 |
| pnetcdf/1.7.0 | pnetcdf/1.10.0 |
| siesta-par/4.0 | siesta-par/4.0.2 |
If you used one of the software listed above, we strongly recommend testing during the early user period. We listed a possible replacement version that is close to the unavailable version. However, if it is possible, we recommend using the most recent versions available. You can find the available versions by module spider {software name}. If you have any questions, please contact OSC Help.
Miscellaneous cleanup on MPIs
We clean up miscellaneous MPIs as we have a better and compatible version available. Since it has a compatible version, you should be able to use your applications without issues.
| Removed MPI versions | Compatible MPI versions |
|---|---|
|
mvapich2/2.3b mvapich2/2.3rc1 mvapich2/2.3rc2 |
mvapich2/2.3 mvapich2/2.3.3 |
|
mvapich2/2.3b-gpu mvapich2/2.3rc1-gpu mvapich2/2.3rc2-gpu mvapich2/2.3-gpu mvapich2/2.3.1-gpu mvapich2-gdr/2.3.1, 2.3.2, 2.3.3 |
mvapich2-gdr/2.3.4 |
|
openmpi/1.10.5 openmpi/1.10 |
openmpi/1.10.7 openmpi/1.10.7-hpcx |
|
openmpi/2.0 openmpi/2.0.3 openmpi/2.1.2 |
openmpi/2.1.6 openmpi/2.1.6-hpcx |
|
openmpi/4.0.2 openmpi/4.0.2-hpcx |
openmpi/4.0.3 openmpi/4.0.3-hpcx |
Software flag usage update for Licensed Software
We have software flags required to use in job scripts for licensed software, such as ansys, abauqs, or schrodinger. With the slurm migration, we updated the syntax and added extra software flags. It is very important everyone follow the procedure below. If you don't use the software flags properly, jobs submitted by others can be affected.
We require using software flags only for the demanding software and the software features in order to prevent job failures due to insufficient licenses. When you use the software flags, Slurm will record it on its license pool, so that other jobs will launch when there are enough licenses available. This will function correctly when everyone uses the software flag.
During the early user period until Dec 15, 2020, the software flag system may not work correctly. This is because, during the test period, licenses will be used from two separate Owens systems. However, we recommend you to test your job scripts with the new software flags, so that you can use it without any issues after the slurm migration.
The new syntax for software flags is
#SBATCH -L {software flag}@osc:N
where N is the requesting number of the licenses. If you need more than one software flags, you can use
#SBATCH -L {software flag1}@osc:N,{software flag2}@osc:M
For example, if you need 2 abaqus and 2 abaqusextended license features, then you can use
$SBATCH -L abaqus@osc:2,abaqusextended@osc:2
We have the full list of software associated with software flags in the table below.
| Software flag | Note | |
|---|---|---|
| abaqus |
abaqus, abaquscae |
|
| ansys | ansys, ansyspar | |
| comsol | comsolscript | |
| schrodinger | epik, glide, ligprep, macromodel, qikprop | |
| starccm | starccm, starccmpar | |
| stata | stata | |
| usearch | usearch | |
| ls-dyna, mpp-dyna | lsdyna |
Owens Programming Environment (PBS)
This document is obsoleted and kept as a reference to previous Owens programming environment. Please refer to here for the latest version.
Compilers
C, C++ and Fortran are supported on the Owens cluster. Intel, PGI and GNU compiler suites are available. The Intel development tool chain is loaded by default. Compiler commands and recommended options for serial programs are listed in the table below. See also our compilation guide.
The Haswell and Broadwell processors that make up Owens support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use.
In our experience, the Intel and PGI compilers do a much better job than the GNU compilers at optimizing HPC code.
With the Intel compilers, use -xHost and -O2 or higher. With the GNU compilers, use -march=native and -O3. The PGI compilers by default use the highest available instruction set, so no additional flags are necessary.
This advice assumes that you are building and running your code on Owens. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
| LANGUAGE | INTEL EXAMPLE | PGI EXAMPLE | GNU EXAMPLE |
|---|---|---|---|
| C | icc -O2 -xHost hello.c | pgcc -fast hello.c | gcc -O3 -march=native hello.c |
| Fortran 90 | ifort -O2 -xHost hello.f90 | pgf90 -fast hello.f90 | gfortran -O3 -march=native hello.f90 |
| C++ | icpc -O2 -xHost hello.cpp | pgc++ -fast hello.cpp | g++ -O3 -march=native hello.cpp |
Parallel Programming
MPI
OSC systems use the MVAPICH2 implementation of the Message Passing Interface (MPI), optimized for the high-speed Infiniband interconnect. MPI is a standard library for performing parallel processing using a distributed-memory model. For more information on building your MPI codes, please visit the MPI Library documentation.
Parallel programs are started with the mpiexec command. For example,
mpiexec ./myprog
The mpiexec command will normally spawn one MPI process per CPU core requested in a batch job. Use the -n and/or -ppn option to change that behavior.
The table below shows some commonly used options. Use mpiexec -help for more information.
| MPIEXEC Option | COMMENT |
|---|---|
-ppn 1 |
One process per node |
-ppn procs |
procs processes per node |
-n totalprocs-np totalprocs |
At most totalprocs processes per node |
-prepend-rank |
Prepend rank to output |
-help |
Get a list of available options |
OpenMP
The Intel, PGI and GNU compilers understand the OpenMP set of directives, which support multithreaded programming. For more information on building OpenMP codes on OSC systems, please visit the OpenMP documentation.
GPU Programming
160 Nvidia P100 GPUs are available on Owens. Please visit our GPU documentation.
Owens Programming Environment
Compilers
C, C++ and Fortran are supported on the Owens cluster. Intel, PGI and GNU compiler suites are available. The Intel development tool chain is loaded by default. Compiler commands and recommended options for serial programs are listed in the table below. See also our compilation guide.
The Haswell and Broadwell processors that make up Owens support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use.
In our experience, the Intel and PGI compilers do a much better job than the GNU compilers at optimizing HPC code.
With the Intel compilers, use -xHost and -O2 or higher. With the GNU compilers, use -march=native and -O3. The PGI compilers by default use the highest available instruction set, so no additional flags are necessary.
This advice assumes that you are building and running your code on Owens. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
| LANGUAGE | INTEL | GNU | PGI |
|---|---|---|---|
| C | icc -O2 -xHost hello.c | gcc -O3 -march=native hello.c | pgcc -fast hello.c |
| Fortran 77/90 | ifort -O2 -xHost hello.F | gfortran -O3 -march=native hello.F | pgfortran -fast hello.F |
| C++ | icpc -O2 -xHost hello.cpp | g++ -O3 -march=native hello.cpp | pgc++ -fast hello.cpp |
Parallel Programming
MPI
OSC systems use the MVAPICH2 implementation of the Message Passing Interface (MPI), optimized for the high-speed Infiniband interconnect. MPI is a standard library for performing parallel processing using a distributed-memory model. For more information on building your MPI codes, please visit the MPI Library documentation.
MPI programs are started with the srun command. For example,
#!/bin/bash
#SBATCH --nodes=2
srun [ options ] mpi_prog
The srun command will normally spawn one MPI process per task requested in a Slurm batch job. Use the --ntasks-per-node=n option to change that behavior. For example,
#!/bin/bash #SBATCH --nodes=2 # Use the maximum number of CPUs of two nodes srun ./mpi_prog # Run 8 processes per node srun -n 16 --ntasks-per-node=8 ./mpi_prog
The table below shows some commonly used options. Use srun -help for more information.
| OPTION | COMMENT |
|---|---|
--ntasks-per-node=n |
number of tasks to invoke on each node |
-help |
Get a list of available options |
srun in any circumstances.OpenMP
The Intel, GNU and PGI compilers understand the OpenMP set of directives, which support multithreaded programming. For more information on building OpenMP codes on OSC systems, please visit the OpenMP documentation.
An OpenMP program by default will use a number of threads equal to the number of CPUs requested in a Slurm batch job. To use a different number of threads, set the environment variable OMP_NUM_THREADS. For example,
#!/bin/bash #SBATCH --ntasks-per-node=8 # Run 8 threads ./omp_prog # Run 4 threads export OMP_NUM_THREADS=4 ./omp_prog
To run a OpenMP job on an exclusive node:
#!/bin/bash #SBATCH --nodes=1 #SBATCH --exclusive export OMP_NUM_THREADS=$SLURM_CPUS_ON_NODE ./omp_prog
Interactive job only
See the section on interactive batch in batch job submission for details on submitting an interactive job to the cluster.
Hybrid (MPI + OpenMP)
An example of running a job for hybrid code:
#!/bin/bash #SBATCH --nodes=2 # Run 4 MPI processes on each node and 7 OpenMP threads spawned from a MPI process export OMP_NUM_THREADS=7 srun -n 8 -c 7 --ntasks-per-node=4 ./hybrid_prog
Tuning Parallel Program Performance: Process/Thread Placement
To get the maximum performance, it is important to make sure that processes/threads are located as close as possible to their data, and as close as possible to each other if they need to work on the same piece of data, with given the arrangement of node, sockets, and cores, with different access to RAM and caches.
While cache and memory contention between threads/processes are an issue, it is best to use scatter distribution for code.
Processes and threads are placed differently depending on the computing resources you requste and the compiler and MPI implementation used to compile your code. For the former, see the above examples to learn how to run a job on exclusive nodes. For the latter, this section summarizes the default behavior and how to modify placement.
OpenMP only
For all three compilers (Intel, GNU, PGI), purely threaded codes do not bind to particular CPU cores by default. In other words, it is possible that multiple threads are bound to the same CPU core.
The following table describes how to modify the default placements for pure threaded code:
| DISTRIBUTION | Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place threads as closely as possible on sockets | Distribute threads as evenly as possible across sockets |
| INTEL | KMP_AFFINITY=compact | KMP_AFFINITY=scatter |
| GNU | OMP_PLACES=sockets[1] | OMP_PROC_BIND=spread/close |
| PGI[2] |
MP_BIND=yes |
MP_BIND=yes |
- Threads in the same socket might be bound to the same CPU core.
- PGI LLVM-backend (version 19.1 and later) does not support thread/processors affinity on NUMA architecture. To enable this feature, compile threaded code with
--Mnollvmto use proprietary backend.
MPI Only
For MPI-only codes, MVAPICH2 first binds as many processes as possible on one socket, then allocates the remaining processes on the second socket so that consecutive tasks are near each other. Intel MPI and OpenMPI alternately bind processes on socket 1, socket 2, socket 1, socket 2 etc, as cyclic distribution.
For process distribution across nodes, all MPIs first bind as many processes as possible on one node, then allocates the remaining processes on the second node.
The following table describe how to modify the default placements on a single node for MPI-only code with the command srun:
| DISTRIBUTION (single node) |
Compact | Scatter/Cyclic |
|---|---|---|
| DESCRIPTION | Place processs as closely as possible on sockets | Distribute process as evenly as possible across sockets |
| MVAPICH2[1] | Default | MV2_CPU_BINDING_POLICY=scatter |
| INTEL MPI | srun --cpu-bind="map_cpu:$(seq -s, 0 2 27),$(seq -s, 1 2 27)" | Default |
| OPENMPI | srun --cpu-bind="map_cpu:$(seq -s, 0 2 27),$(seq -s, 1 2 27)" | Default |
MV2_CPU_BINDING_POLICYwill not work ifMV2_ENABLE_AFFINITY=0is set.
To distribute processes evenly across nodes, please set SLURM_DISTRIBUTION=cyclic.
Hybrid (MPI + OpenMP)
For Hybrid codes, each MPI process is allocated OMP_NUM_THREADS cores and the threads of each process are bound to those cores. All MPI processes (as well as the threads bound to the process) behave as we describe in the previous sections. It means the threads spawned from a MPI process might be bound to the same core. To change the default process/thread placmements, please refer to the tables above.
Summary
The above tables list the most commonly used settings for process/thread placement. Some compilers and Intel libraries may have additional options for process and thread placement beyond those mentioned on this page. For more information on a specific compiler/library, check the more detailed documentation for that library.
GPU Programming
160 Nvidia P100 GPUs are available on Owens. Please visit our GPU documentation.
Reference
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Owens, please use the following Archival Resource Key:
ark:/19495/hpc6h5b1
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2016. Owens Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:19495/hpc6h5b1
Here is the citation in BibTeX format:
@misc{Owens2016,
ark = {ark:/19495/hpc93fc8},
url = {http://osc.edu/ark:/19495/hpc6h5b1},
year = {2016},
author = {Ohio Supercomputer Center},
title = {Owens Supercomputer}
}
And in EndNote format:
%0 Generic %T Owens Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc6h5b1 %U http://osc.edu/ark:/19495/hpc6h5b1 %D 2016
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Owens SSH key fingerprints
These are the public key fingerprints for Owens:
owens: ssh_host_rsa_key.pub = 18:68:d4:b0:44:a8:e2:74:59:cc:c8:e3:3a:fa:a5:3f
owens: ssh_host_ed25519_key.pub = 1c:3d:f9:99:79:06:ac:6e:3a:4b:26:81:69:1a:ce:83
owens: ssh_host_ecdsa_key.pub = d6:92:d1:b0:eb:bc:18:86:0c:df:c5:48:29:71:24:af
These are the SHA256 hashes:
owens: ssh_host_rsa_key.pub = SHA256:vYIOstM2e8xp7WDy5Dua1pt/FxmMJEsHtubqEowOaxo
owens: ssh_host_ed25519_key.pub = SHA256:FSb9ZxUoj5biXhAX85tcJ/+OmTnyFenaSy5ynkRIgV8
owens: ssh_host_ecdsa_key.pub = SHA256:+fqAIqaMW/DUJDB0v/FTxMT9rkbvi/qVdMKVROHmAP4
Batch Limit Rules
Memory Limit:
A small portion of the total physical memory on each node is reserved for distributed processes. The actual physical memory available to user jobs is tabulated below.
Summary
| Node type | default and max memory per core | max memory per node |
|---|---|---|
| regular compute | 4.214 GB | 117 GB |
| huge memory | 31.104 GB | 1492 GB |
| gpu | 4.214 GB | 117 GB |
e.g. The following slurm directives will actually grant this job 3 cores, with 10 GB of memory
(since 2 cores * 4.2 GB = 8.4 GB doesn't satisfy the memory request).
#SBATCH --ntasks-per-node=2
#SBATCH --mem=10gIt is recommended to let the default memory apply unless more control over memory is needed.
Note that if an entire node is requested, then the job is automatically granted the entire node's main memory. On the other hand, if a partial node is requested, then memory is granted based on the default memory per core.
See a more detailed explanation below.
Regular Dense Compute Node
On Owens, it equates to 4,315 MB/core or 120,820 MB/node (117.98 GB/node) for the regular dense compute node.
If your job requests less than a full node ( ntasks-per-node < 28 ), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (4315 MB/core). For example, without any memory request ( mem=XXMB ), a job that requests --nodes=1 --ntasks-per-node=1 will be assigned one core and should use no more than 4315 MB of RAM, a job that requests --nodes=1 --ntasks-per-node=3 will be assigned 3 cores and should use no more than 3*4315 MB of RAM, and a job that requests --nodes=1 --ntasks-per-node=28 will be assigned the whole node (28 cores) with 118 GB of RAM.
Here is some information when you include memory request (mem=XX ) in your job. A job that requests --nodes=1 --ntasks-per-node=1 --mem=12GB will be assigned three cores and have access to 12 GB of RAM, and charged for 3 cores worth of usage (in other ways, the request --ntasks-per-node is ingored). A job that requests --nodes=1 --ntasks-per-node=5 --mem=12GB will be assigned 5 cores but have access to only 12 GB of RAM, and charged for 5 cores worth of usage.
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 118 GB/node and charged for the entire nodes regardless of ppn request. For example, a job that requests --nodes=10 --ntasks-per-node=1 will be charged for 10 whole nodes (28 cores/node*10 nodes, which is 280 cores worth of usage).
Huge Memory Node
On Owens, it equates to 31,850 MB/core or 1,528,800 MB/node (1,492.96 GB/node) for a huge memory node.
To request no more than a full huge memory node, you have two options:
- The first is to specify the memory request between 120,832 MB (118 GB) and 1,528,800 MB (1,492.96 GB), i.e.,
120832MB <= mem <=1528800MB(118GB <= mem < 1493GB). Note: you can only use interger for request - The other option is to use the combination of
--ntasks-per-nodeand--partition, like--ntasks-per-node=4 --partition=hugemem. When no memory is specified for the huge memory node, your job is entitled to a memory allocation proportional to the number of cores requested (31,850MB/core). Note,--ntasks-per-nodeshould be no less than 4 and no more than 48.
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
GPU Jobs
There is only one GPU per GPU node on Owens.
For serial jobs, we allow node sharing on GPU nodes so a job may request any number of cores (up to 28)
(--nodes=1 --ntasks-per-node=XX --gpus-per-node=1)
For parallel jobs (n>1), we do not allow node sharing.
See this GPU computing page for more information.
Partition time and job size limits
Here are the partitions available on Owens:
| Name | Max time limit (dd-hh:mm:ss) |
Min job size | Max job size | notes |
|---|---|---|---|---|
|
serial |
7-00:00:00 |
1 core |
1 node |
|
|
longserial |
14-00:00:0 |
1 core |
1 node |
|
|
parallel |
4-00:00:00 |
2 nodes |
81 nodes |
|
| gpuserial | 7-00:00:00 | 1 core | 1 node | |
| gpuparallel | 4-00:00:00 | 2 nodes | 8 nodes | |
|
hugemem |
7-00:00:00 |
1 core |
1 node |
|
| hugemem-parallel | 4-00:00:00 | 2 nodes | 16 nodes |
|
| debug | 1:00:00 | 1 core | 2 nodes |
|
| gpudebug | 1:00:00 | 1 core | 2 nodes |
|
--partition=<partition-name> to the sbatch command at submission time or add this line to the job script:#SBATCH --paritition=<partition-name>To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if the performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
Job/Core Limits
| Max Running Job Limit | Max Core/Processor Limit | Max node Limit | ||||
|---|---|---|---|---|---|---|
| For all types | GPU jobs | Regular debug jobs | GPU debug jobs | For all types | hugemem | |
| Individual User | 384 | 132 | 4 | 4 | 3080 | 12 |
| Project/Group | 576 | 132 | n/a | n/a | 3080 | 12 |
An individual user can have up to the max concurrently running jobs and/or up to the max processors/cores in use.
However, among all the users in a particular group/project, they can have up to the max concurrently running jobs and/or up to the max processors/cores in use.
Owens cluster history by the numbers
The Owens high performance computing (HPC) cluster, decommissioned in February 2025, ran more than 36 million jobs during its time at the OSC data center. The $9.7 million system, which launched in 2016, was named for Ohio native and Olympic champion J.C. “Jesse” Owens.
At the time of its launch, Owens boasted nearly 10 times the performance power of any previous OSC system. During the cluster’s lifespan, OSC observed a growing number of clients use its GPUs for artificial intelligence and machine learning work. In addition, Owens featured a novel cooling system with rear door heat exchangers.
The cluster’s lifetime usage statistics, captured by OSC below, reflect several trends over the past decade: clients’ rising use of GPUs and Python for data analysis, as well as an increase in commercial clients.
|
Job Stats: |
Number: |
% of Total: |
|
Total jobs run |
36,154,977 |
|
|
Jobs that requested GPUs |
2,110,504 |
5.8% |
|
Jobs that requested Big Memory |
439,542 |
1.2% |
|
Jobs that used a single core |
10,197,238 |
28.2% |
|
Jobs that used no more than a single node (28 cores) |
34,916,359 |
96.6% |
|
Jobs that used more than 81 nodes / 2,268 cores (default maximum allowed) |
2,949 |
0.01% |
|
Jobs completed in less than 1 hour |
28,638,060 |
79.2% |
|
Jobs that waited less than 30 minutes in the queue |
27,777,842 |
76.8% |
Timing Stats:
-
Total core hours: 1,131,350,805
-
Total GPU hours: 6,418,404
-
Average wall time used: 1 hour, 11 minutes, 27 seconds
-
Average queue wait time: 1 hour, 3 minutes, 38 seconds
-
Longest running job: 30 days, 28 seconds
-
First job start time: 2016-08-27 12:06:07
-
Last job end time: 2025-02-03 06:46:32
-
Elapsed time between first and last jobs: 8 years, 5 months, 6 days, 15 hours, 5 minutes, 19 seconds
-
Physical delivery: 2016-06-06
-
Physical removal of last components from the State of Ohio Computer Center (SOCC): 2025-05-01
Client Stats:
-
Count of distinct projects that ran jobs: 2,292
-
Count of distinct users that ran jobs: 10,284
-
Most active user by core hours: Minkyu Kim, The Ohio State University (31,616,854 / 2.8% of total)
-
Most active user by jobs run: Balasubramanian Ganesan, Mars Incorporated (3,357,138 / 9.3% of total)
-
Most active project by core hours: PAA0023 “SIMCenter,” Ohio State (54,212,464 / 4.8% of total)
-
Most active project by jobs run: PYS1083 “Mars Genome Assembly,” Mars Incorporated (3,357,138 / 9.3% of total)
-
First non-staff member to run a job: Greg Padgett, TotalSim (2016-08-27)
-
Last non-staff member to run a job: Mason Pacenta, Ohio State (2025-02-03)
Misc Stats:
-
Most run application: Python
-
5,787,724 jobs (16.0% of total)
-
98,653,602 core hours (8.7% of total)
-
822,760 GPU hours
-
Average cores used per job: 15
-
Average lifetime utilization: 65.4%
Owens cluster transition: Action required
After eight years of service, the Owens high performance computing (HPC) cluster will be decommissioned over the next two months. Clients currently using Owens for research and classroom instruction must migrate jobs to other OSC clusters during this time.
To assist clients with transitioning their workflows, Owens will be decommissioned in two phases. On Jan. 6, 2025, OSC will move two-thirds of the regular compute nodes and one-half of the GPU nodes (a total of about 60% of the cluster cores) offline. The remainder of the nodes will power down on Feb. 3, 2025.
OSC will remove any remaining licensed software from Owens on Dec. 17, 2024. Abaqus, Ansys, LS-DYNA and Star-CCM+ are now available on the Cardinal cluster for all academic users.
Owens clients can migrate jobs to the Pitzer, Ascend or Cardinal clusters; classroom instructors should prepare all forthcoming courses on one of these systems. If you are using Jupyter/RStudio classroom apps, please prepare courses on Pitzer.
Cardinal, OSC’s newest cluster, became available for all clients to use on Nov. 4, 2024. A new ScarletCanvas course, “Getting Started with Cardinal,” provides an overview of this HPC resource and how to use it. Visit the OSC course module on ScarletCanvas to enroll in and complete the course, which is available in an asynchronous format.
In addition to launching Cardinal, OSC is transitioning the data center space occupied by the Owens cluster to accommodate an expansion of the Ascend cluster. The new resources are expected to be available for client use in March 2025. More details will be released in January.
Thank you for your cooperation in transitioning your workflows. If you discover that a software package you are using on Owens is currently not supported on the other clusters, you may install it locally or contact oschelp@osc.edu for assistance.
OSC is excited to offer our clients new and improved HPC resources that will benefit your research, classroom and innovation initiatives. For more information about our cluster transition, please visit the OSC site.
AMD Linux cluster (MPP)
 OSC engineers in March, 2002, installed a 256-CPU AMD Linux Cluster. The 32-bit Parallel Processing (MPP) system featured one gigabyte of distributed memory, 256 1.4 & 1.53 gigahertz AMD Athlon processors and a Myrinet and Fast Ethernet interconnect.
OSC engineers in March, 2002, installed a 256-CPU AMD Linux Cluster. The 32-bit Parallel Processing (MPP) system featured one gigabyte of distributed memory, 256 1.4 & 1.53 gigahertz AMD Athlon processors and a Myrinet and Fast Ethernet interconnect.
Apple Xserve G5 Cluster
 next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.
next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.BALE cluster
 In July, 2002, OSC officials put the finishing touches on a $1.5 million, 7,040-square-foot expansion called the Blueprint for Advanced Learning Environment, or BALE. OSC deployed more than 50 NVIDIA Quadro™4 900 XGL workstation graphics boards to power the BALE Cluster for volume rendering of graphics applications.
In July, 2002, OSC officials put the finishing touches on a $1.5 million, 7,040-square-foot expansion called the Blueprint for Advanced Learning Environment, or BALE. OSC deployed more than 50 NVIDIA Quadro™4 900 XGL workstation graphics boards to power the BALE Cluster for volume rendering of graphics applications.
BALE provided an environment for testing and validating the effectiveness of new tools, technologies and systems in a workplace setting, including a theater, conference space and the OSC Interface Lab. BALE Theater featured about 40 computer workstations powered by a visualization cluster. When workstations were not being used in the Theatre, the cluster was used for parallel computation and large scientific data visualization.
Near the end of January 2007, OSC upgraded its BALE Cluster, a distributed/shared memory hybrid system constructed from commodity PC components running the Linux OS. The more powerful system resided in a separate server room from OSC’s on-site training facility, eliminating classroom noise and heat generated from the computers. This improved environment allowed students to run hands-on exercises faster without distractions. The updated cluster boasted 55 rack-mounted compute nodes. Each node contained a dual core AMD Athlon 64 processor integrated with nVIDIA GeForce 6150 graphics processing units (GPU). An application taking full advantage of the system, using all AMD and nVIDIA processing units, could reach one trillion calculations per second.
Beowulf
In April, 1999, OSC installed a 10-CPU IA32 Linux Cluster as a “Beowulf Cluster,” a system built of commodity off-the-shelf (COTS) components dedicated for parallel use and running an open source operating system and tool set. OSC developed this cluster to create an experimental test bed for testing new parallel algorithms and commodity communications hardware, to design a model system for cluster systems to be set up by members of the OSC user community and to establish a high performance parallel computer system in its own right.
Brain
 Later in 1999, OSC purchased a cluster of 33 SGI 1400L systems (running Linux). These systems were connected with Myricom's Myrinet high-speed network and used as a “Beowulf cluster on steroids.” This cluster, nicknamed the Brain (after Pinky's smarter half on Animaniacs), was initially assembled and tested in one of SGI's HPC systems labs in Mountain View, Calif., in October. It was then shipped to Portland, Ore., where it was featured and demoed prominently in SGI's booth at the Supercomputing '99 conference. After SC99, the cluster was dismantled and shipped to OSC’s offices, where it was permanently installed.
Later in 1999, OSC purchased a cluster of 33 SGI 1400L systems (running Linux). These systems were connected with Myricom's Myrinet high-speed network and used as a “Beowulf cluster on steroids.” This cluster, nicknamed the Brain (after Pinky's smarter half on Animaniacs), was initially assembled and tested in one of SGI's HPC systems labs in Mountain View, Calif., in October. It was then shipped to Portland, Ore., where it was featured and demoed prominently in SGI's booth at the Supercomputing '99 conference. After SC99, the cluster was dismantled and shipped to OSC’s offices, where it was permanently installed.
CRAY T3E
 In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T3E-600/LC housed 136 Alpha EV5 processors at 300MHz and 16GB of memory.
In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T3E-600/LC housed 136 Alpha EV5 processors at 300MHz and 16GB of memory.
CRAY T94
 In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T94 featured four custom vector processors at 450MHz and 1GB of memory.
In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T94 featured four custom vector processors at 450MHz and 1GB of memory.
Convex Exemplar SPP1220
 OSC engineers in 1995 installed a Convex Exemplar SPP1220 system, a recently upgraded version of Convex’s popular SPP1000 system, featuring a new processor, memory and I/O package.
OSC engineers in 1995 installed a Convex Exemplar SPP1220 system, a recently upgraded version of Convex’s popular SPP1000 system, featuring a new processor, memory and I/O package.
Cray J90se
 In June, 1997, OSC engineers installed the Cray J90se system. This Scalar Enhanced series doubled the scalar speed of the processors on the base J90 model to 200 MHz; the vector chip remained at 100 MHz.
In June, 1997, OSC engineers installed the Cray J90se system. This Scalar Enhanced series doubled the scalar speed of the processors on the base J90 model to 200 MHz; the vector chip remained at 100 MHz.
Cray SV1
 In October, 1999, OSC engineers installed a Cray SV1 system with 16 custom vector processors at 300MHz and 16GB of memory. The SV1 used complementary metal–oxide–semiconductor (CMOS) processors, which lowered the cost of the system, and allowed the computer to be air-cooled.
In October, 1999, OSC engineers installed a Cray SV1 system with 16 custom vector processors at 300MHz and 16GB of memory. The SV1 used complementary metal–oxide–semiconductor (CMOS) processors, which lowered the cost of the system, and allowed the computer to be air-cooled.
In 2004, OSC announced an upgrade to its SV-1ex vector supercomputer that increased its processing capacity by 33 percent. With the addition of eight new processors, peak performance was then 64 Gigaflops, delivering the computing power of roughly 64 billion calculators all yielding an answer each and every second. Originally purchased in 1999, the SV1ex upgrade significantly increases the performance capacity of a system that had proven to be a workhorse for the research community.
Cray T3D MPP
 On April 18, 1994, OSC engineers took delivery of a 32-processor Cray T3D MPP, an entry-level massively parallel processing system. Each of the processors included a DEC Alpha chip, eight megawords of memory and Cray-designed memory logic.
On April 18, 1994, OSC engineers took delivery of a 32-processor Cray T3D MPP, an entry-level massively parallel processing system. Each of the processors included a DEC Alpha chip, eight megawords of memory and Cray-designed memory logic.
Cray X-MP/24
 Ohio State in the spring of 1987 budgeted $8.2 million over the next five years to lease a Cray X-MP/24, OSP’s first real supercomputer. The X-MP arrived June 1 at the OSU IRCC loading dock on Kinnear Road.
Ohio State in the spring of 1987 budgeted $8.2 million over the next five years to lease a Cray X-MP/24, OSP’s first real supercomputer. The X-MP arrived June 1 at the OSU IRCC loading dock on Kinnear Road.
Cray X1
 The OSC-Springfield offices would officially open in April 2004. Over the next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.
The OSC-Springfield offices would officially open in April 2004. Over the next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.Cray XD1
Cray Y-MP 2E
 In 1994 OSC installed a Cray Y-MP 2E as a complement machine to the Cray T3D MPP.
In 1994 OSC installed a Cray Y-MP 2E as a complement machine to the Cray T3D MPP.
Cray Y-MP8/864
 In August 1989, OSC engineers completed the installation of the $22 million Cray Y-MP8/864 system, which was deemed the largest and fastest supercomputer in the world for a short time. The seven-ton system was able to calculate 200 times faster than many mainframes at that time and underwent several weeks of stress testing from “friendly users, who loaded the machine to 97 percent capacity for 17 consecutive days.
In August 1989, OSC engineers completed the installation of the $22 million Cray Y-MP8/864 system, which was deemed the largest and fastest supercomputer in the world for a short time. The seven-ton system was able to calculate 200 times faster than many mainframes at that time and underwent several weeks of stress testing from “friendly users, who loaded the machine to 97 percent capacity for 17 consecutive days.
“The lightning speed of the supercomputer allows scientists to work massive problems in real-time, without having to wait days or weeks for the results of larger computer runs,” according to a Sept. 28, 1989, article in Ohio State’s faculty and staff newsletter, OnCampus. “The CRAY Y-MP8/864 performs 2.7 billion calculations per second.”
Glenn

The Ohio Supercomputer Center's IBM Cluster 1350, named "Glenn", features AMD Opteron multi-core technologies. The system offers a peak performance of more than 54 trillion floating point operations per second and a variety of memory and processor configurations. The current Glenn Phase II components were installed and deployed in 2009, while the earlier phase of Glenn – now decommissioned – had been installed and deployed in 2007.
 03/24/2016: Glenn Cluster has been retired. Please see our FAQ page.
03/24/2016: Glenn Cluster has been retired. Please see our FAQ page.Hardware
The hardware configuration consisted of the following:
- 436 System x3455 compute nodes
- Dual socket, quad core 2.5 GHz Opterons
- 24 GB RAM
- 393 GB local disk space in /tmp
- 2 System x3755 login nodes
- Quad socket quad core 2.4 GHz Opterons
- 64 GB RAM
- Voltaire 20 Gbps PCI Express adapters
There were 36 GPU-capable nodes on Glenn, connected to 18 Quadro Plex S4's for a total of 72 CUDA-enabled graphics devices. Each node had access to two Quadro FX 5800-level graphics cards.
- Each Quadro Plex S4 had these specs:
- Each Quadro Plex S4 contains 4 Quadro FX 5800 GPUs
- 240 cores per GPU
- 4GB Memory per card
- The 36 compute nodes in Glenn contained:
- Dual socket, quad core 2.5 GHz Opterons
- 24 GB RAM
- 393 GB local disk space in '/tmp'
- 20Gb/s Infiniband ConnectX host channel adapater (HCA)
How to Connect
To connect to Glenn, ssh to glenn.osc.edu.
Batch Specifics
Refer to the documenation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- All compute nodes on Glenn are 8 cores/processors per node (ppn). Parallel jobs must use
ppn=8. - If you need more than 24 GB of RAM per node, you will need to run your job on Oakley.
- GPU jobs must request whole nodes (ppn=8) and are allocated two GPUs each.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Batch Limit Rules
Memory Limit:
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs. On Glenn, it equates to 3GB/core and 24GB/node.
If your job requests less than a full node ( ppn<8 ), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (3GB/ core). For example, without any memory request ( mem=XX ), a job that requests nodes=1:ppn=1 will be assigned one core and should use no more than 3GB of RAM, a job that requests nodes=1:ppn=3 will be assigned 3 cores and should use no more than 9GB of RAM, and a job that requests nodes=1:ppn=8 will be assigned the whole node (8 cores) with 24GB of RAM. It is important to keep in mind that the memory limit ( mem=XX ) you set in PBS does not work the way one might expect it to on Glenn. It does not cause your job to be allocated the requested amount of memory, nor does it limit your job’s memory usage. For example, a job that requests nodes=1:ppn=1,mem=9GB will be assigned one core (which means you should use no more than 3GB of RAM instead of the requested 9GB of RAM) and you were only charged for one core worth of Resource Units (RU).
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 24GB/node. Jobs requesting more than 24GB/node should be submitted to other clusters (Oakley or Ruby)
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
Walltime Limit
Here are the queues available on Glenn:
|
NAME |
MAX WALLTIME |
NOTES |
|---|---|---|
|
Serial |
168 hours |
|
|
Longserial |
336 hours |
Restricted access |
|
Parallel |
96 hours |
|
Job Limit
An individual user can have up to 128 concurrently running jobs and/or up to 2048 processors/cores in use. All the users in a particular group/project can among them have up to 192 concurrently running jobs and/or up to 2048 processors/cores in use. Jobs submitted in excess of these limits are queued but blocked by the scheduler until other jobs exit and free up resources.
A user may have no more than 1,000 jobs submitted to a queue; parallel and serial job queues are treated separately. Jobs submitted in excess of these limits will be rejected.
Citation
Glenn retired from service on March 24, 2016.
To cite Glenn, please use the following Archival Resource Key:
ark:/19495/hpc1ph70
Here is the citation in BibTeX format:
@article{Glenn2009,
ark = {ark:/19495/hpc1ph70},
url = {http://osc.edu/ark:/19495/hpc1ph70},
year = {2009},
author = {Ohio Supercomputer Center},
title = {Glenn supercomputer}
}
And in EndNote format:
%0 Generic %T Glenn supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc1ph70 %U http://osc.edu/ark:/19495/hpc1ph70 %D 2009
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Glenn Retirement
Glenn Cluster Retired: March 24, 2016
The Glenn Cluster supercomputer has been retired from service to make way for a much more powerful new system. As an OSC client, the removal of the cluster will result in work being added to the heavy workload being handled by Oakley or Ruby, potentially impacting you.
Why is Glenn being retired?
Glenn is our oldest and least efficient cluster. In order to make room for our new cluster, to be installed later in 2016, we must remove Glenn to prepare the space and do some facilities work.
How will this impact me?
Demand for computing services is already high, and removing approximately 20 percent of our total FLOP capability will likely result in more time spent waiting in the queue. Please be patient with the time it takes for your jobs to run. We will be monitoring the queues, and may make scheduler adjustments to achieve better efficiency.
How long will it take before the new cluster is online?
We expect the new cluster to be partially deployed by Aug. 1, and completely deployed by Oct. 1. Even in the partially deployed state, there will be more available nodes: 1.5x more cores, and roughly 3x more FLOPs available than there are today.
Is there more information on the new cluster?
Please see our webpage: https://www.osc.edu/supercomputing/computing/c16.
Need help, or have further questions?
We will help. Please let us know if you have any paper deadlines or similar requirements. We may be able to make some adjustments to make your work more efficient, or to help it get through the queue more quickly. To see what things you should consider if you have work to migrate off of Glenn, please visit https://www.osc.edu/glennretirement.
Please contact OSC Help, our 24/7 help desk.
Toll Free: (800) 686-6472
Local: (614) 292-1800
Email: oschelp@osc.edu
Queues and Reservations
Here are the queues available on Glenn. Please note that you will be routed to the appropriate queue based on your walltime and job size request.
| Name | Nodes available | max walltime | max job size | notes |
|---|---|---|---|---|
|
Serial |
Available minus reservations |
168 hours |
1 node |
|
|
Longserial |
Available minus reservations |
336 hours |
1 node |
Restricted access |
|
Parallel |
Available minus reservations |
96 hours |
256 nodes |
|
|
Dedicated |
Entire cluster |
48 hours |
436 nodes |
Restricted access |
"Available minus reservations" means all nodes in the cluster currently operational (this will fluctuate slightly), less the reservations listed below. To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
In addition, there are a few standing reservations.
| Name | Times | Nodes Available | Max Walltime | Max job size | notes |
|---|---|---|---|---|---|
| Debug | 8AM-6PM Weekdays | 16 | 1 hour | 16 nodes | For small interactive and test jobs. |
| GPU | ALL | 32 | 336 hours | 32 nodes |
Small jobs not requiring GPUs from the serial and parallel queues will backfill on this reservation. |
Occasionally, reservations will be created for specific projects that will not be reflected in these tables.
Glenn Phase I
In June, 2007, OSC purchased a 4212-CPU IBM Opteron Cluster (Phase 1) and named the cluster after former astronaut and statesman John Glenn. The acquisition of the IBM Cluster 1350 included the latest AMD Opteron multi-core technologies and the new IBM cell processors. Ten times as powerful as any of OSC’s current systems, the system offered a peak performance of more than 22 trillion floating point operations per second. OSC’s new supercomputer also included blade systems based on the Cell Broadband Engine processor. This allowed Ohio researchers and industries to easily use this new hybrid HPC architecture.
IBM RISC System/6000* Scalable POWERparallel Systems * SP2
 In April, 1995, OSC engineers began installing a powerful new computer at the OSC/KRC – an IBM RISC System/6000* Scalable POWERparallel Systems * SP2. The SP2 could run several numeric-intensive and data-intensive projects across different processors – which allowed different users across the state to use the SP2 at the same time – or handle a single project quickly by distributing the calculations equally across its available processors.
In April, 1995, OSC engineers began installing a powerful new computer at the OSC/KRC – an IBM RISC System/6000* Scalable POWERparallel Systems * SP2. The SP2 could run several numeric-intensive and data-intensive projects across different processors – which allowed different users across the state to use the SP2 at the same time – or handle a single project quickly by distributing the calculations equally across its available processors.
"We selected the SP2 largely because of its ability to use a high-speed switch to interconnect the processors, and the assignment of disk units to individual nodes in order to optimize parallel I/O," said Al Stutz, OSC's associate director.
Itanium 2 cluster
In October, 2002, OSC engineers installed the 300-CPU HP Workstation Itanium 2 Linux zx6000 Cluster. OSC selected HP’s computing cluster for its blend of high performance, flexibility and low cost. The HP cluster used Myricom's Myrinet high-speed interconnect and ran the Red Hat Linux Advanced Workstation, a 64-bit Linux operating system.
Lego
 OSC engineers were busy again in September of 1998, installing an SGI Origin 2000 system at the Center. The SGI Origin 2000, code named Lego, came from a family of mid-range and high-end servers developed and manufactured by Silicon Graphics Inc. (SGI) to succeed the SGI Challenge and POWER Challenge. The SGI Origin 2000 contained 32 MIPS R12000 processors at 300MHz and 16GB of memory.
OSC engineers were busy again in September of 1998, installing an SGI Origin 2000 system at the Center. The SGI Origin 2000, code named Lego, came from a family of mid-range and high-end servers developed and manufactured by Silicon Graphics Inc. (SGI) to succeed the SGI Challenge and POWER Challenge. The SGI Origin 2000 contained 32 MIPS R12000 processors at 300MHz and 16GB of memory.
PIV cluster
 In December, 2003, OSC engineers installed a 512-CPU Pentium 4 Linux Cluster. Replacing the AMD Athlon cluster, the P4 doubled the existing system’s power with a sizable increase in speed. With a theoretical peak of 2,457 gigaflops, the P4 cluster contained 256 dual-processor Pentium IV Xeon systems with four gigabytes of memory per node and 20 terabytes of aggregate disk space. It was connected via a gigabit Ethernet and used Voltair InfiniBand 4x HCA, and a Voltair ISR 9600 InfiniBand switch router for high-speed interconnect.
In December, 2003, OSC engineers installed a 512-CPU Pentium 4 Linux Cluster. Replacing the AMD Athlon cluster, the P4 doubled the existing system’s power with a sizable increase in speed. With a theoretical peak of 2,457 gigaflops, the P4 cluster contained 256 dual-processor Pentium IV Xeon systems with four gigabytes of memory per node and 20 terabytes of aggregate disk space. It was connected via a gigabit Ethernet and used Voltair InfiniBand 4x HCA, and a Voltair ISR 9600 InfiniBand switch router for high-speed interconnect.
Pinky
Early in 1999, Pinky, a small cluster of five dual-processor Pentium II systems connected with Myrinet, was made available to OSC users on a limited basis. Pinky was named for a good-natured but feebleminded lab mouse in the animated television series Animaniacs.
SGI 750 Itanium Cluster
 In August, 2001, OSC engineers installed a 146-CPU SGI 750 Itanium Linux Cluster, described by SGI as one of the fastest in the world. The system – with 292GB memory, 428GFLOPS peak performance for double-precision computations and 856GFLOPS peak performance for single-precision computations – followed the Pentium® III Xeon™ cluster that had been operated at OSC for the preceding 18 months. This system was the first Itanium processor-based cluster installed by SGI.
In August, 2001, OSC engineers installed a 146-CPU SGI 750 Itanium Linux Cluster, described by SGI as one of the fastest in the world. The system – with 292GB memory, 428GFLOPS peak performance for double-precision computations and 856GFLOPS peak performance for single-precision computations – followed the Pentium® III Xeon™ cluster that had been operated at OSC for the preceding 18 months. This system was the first Itanium processor-based cluster installed by SGI.
SGI Altix 350
SGI Altix 3700
 In September, 2003, OSC engineers installed a SGI Altix 3700 system to replace its SGI Origin 2000 system and to augment its HP Itanium 2 Cluster. The Altix was a non-uniform memory access system with 32 Itanium processors and 64 gigabytes of memory. The Altix featured Itanium 2 processors and runs the Linux operating system. OSC's HP Cluster also included Itanium 2 processors and runs Linux. The cluster and Altix were distinguished by the way memory is accessed and its availability to any or all processors.
In September, 2003, OSC engineers installed a SGI Altix 3700 system to replace its SGI Origin 2000 system and to augment its HP Itanium 2 Cluster. The Altix was a non-uniform memory access system with 32 Itanium processors and 64 gigabytes of memory. The Altix featured Itanium 2 processors and runs the Linux operating system. OSC's HP Cluster also included Itanium 2 processors and runs Linux. The cluster and Altix were distinguished by the way memory is accessed and its availability to any or all processors.
SGI Power Challenge system
In October, 1995 OSC engineers installed an SGI Power Challenge system at the KRC site. The SGI system featured 16 processors, two gigabytes of main memory (8-way interleaved), and four megabytes of secondary cache.
SunFire 6800
 In October, 2001, OSC engineers installed four SunFire 6800 midframe servers, with a total of 72 UltraSPARC III processors.
In October, 2001, OSC engineers installed four SunFire 6800 midframe servers, with a total of 72 UltraSPARC III processors.