The highly ambiguous nature of natural language presents many challenges to researchers who design software to analyze, understand and generate languages that humans use naturally. Shaojun Wang, Ph.D., an assistant professor of Computer Science and Engineering at Wright State University, is leveraging the resources of the Ohio Supercomputer Center to build a statistical language model that will capture various kinds of regularities of natural language to improve the performance of a range of natural language processing applications.
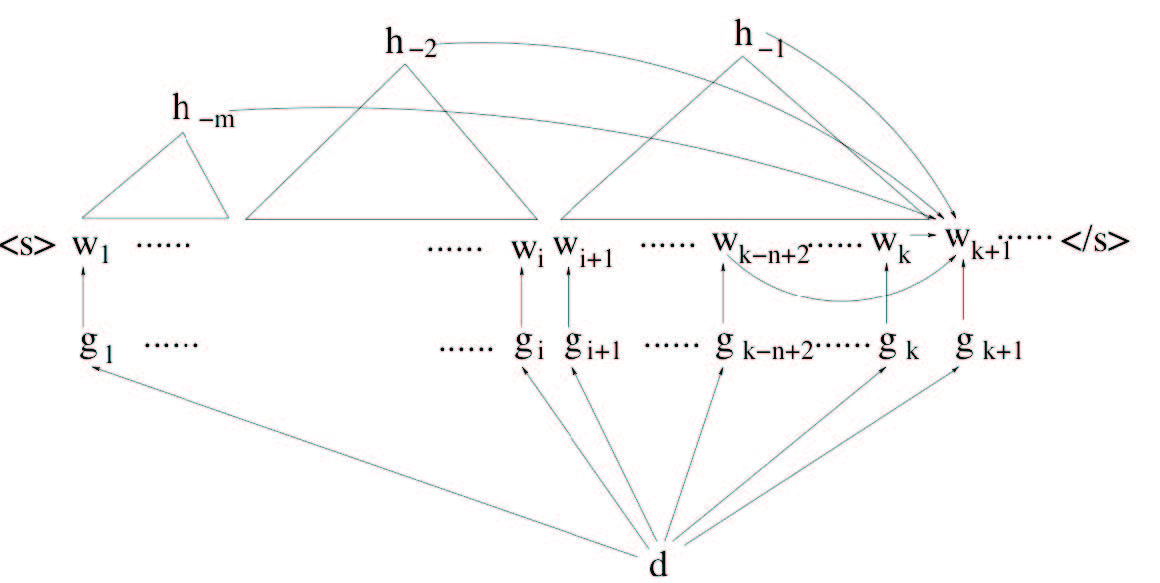
“It has long been a challenge in statistical language modeling to develop a unified framework to integrate various language model components to form a more sophisticated model that is tractable and also performs well empirically,” said Wang. “Natural language encodes messages via complex, hierarchically organized sequences. The local lexical structure of the sequence conveys surface information, whereas the syntactic structure, which encodes long-range dependencies, carries deeper semantic information.”
By exploiting the particular structure of various composite language models, Wang can decompose the seemingly complex statistical representations into simpler ones; this enables the estimation and inference algorithms for the simpler composite language models to become internal building blocks for the estimation of complex composite language models, thus finally solving the estimation problem for extremely complex, high-dimensional distributions.
To evaluate the performance of the composite language models in a real-world scenario, Wang and his colleagues will embed their new models in large-scale machine translation systems to remove language barriers to processing human communication.
--
Project lead: Shaojun Wang, Wright State University
Research title: Exploiting syntactic, semantic and lexical regularities in language modeling
Funding source: National Science Foundation, Google, Wright State University