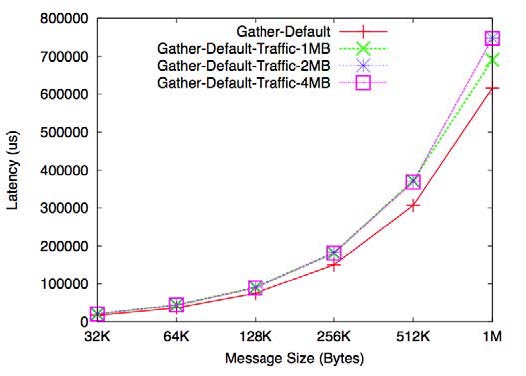
above: Ohio State's Dhabaleswar Panda accessed Ohio Supercomputer Center resources to measure the effect of background traffic on the MPI Gather operation for various message sizes.
Scientific computing is credited for many of the technological breakthroughs of our generation and is used in many fields, ranging from drug discovery and aerospace to weather prediction and seismic analysis. Scientific computation often deals with very large amounts of data, and its algorithms need to compute results from mathematical models. Due to their compute- and data-intensive nature, these applications are often parallel, i.e., they perform calculations simultaneously on multiple computers – from a handful of processors to thousands interconnected by a high-speed communications network.
Message Passing Interface (MPI), the lingua franca of scientific parallel computing, is a library of communications standards that control how software programs communicate with each other and is available on a variety of parallel computer platforms. On the hardware side, InfiniBand is a widely used processor interconnect favored for its open standards and high performance. MVAPICH2 is a popular implementation of the MPI-2 standard prevalent on InfiniBand-based systems.
“It is anticipated that the first exaflop machines (calculating one quintillion floating point operations per second) will be available before the turn of the decade,” said Dhabaleswar K. Panda, Ph.D., an Ohio State University professor of computer science. “As the rates of computation increase further, it is crucial to design processor architectures, networks and applications in a ‘co-designed’ manner, so as to extract the best performance out of the system."
To that end, Panda leads a team (including researchers Karen Tomko and Sayantan Sur) that is co-designing the MVAPICH2 MPI library with the underlying InfiniBand communication network and end applications to significantly improve the efficiency and performance of a system. The team is designing MPI-2 and the proposed MPI-3 one-sided communications using InfiniBand’s Remote Direct Memory Access feature. Additionally, they have developed a design for the upcoming MPI-3 non-blocking collective communication for Ialltoall and Ibcast operations on state-of-the-art network offload technology.
“An underlying design principle in HPC is to expose, not hide, system features that lead to better performance,” Panda said. “However, as system complexity grows, this must be done in a manner that does not overwhelm application developers with detail.”
Tomko, an Ohio Supercomputer Center senior researcher, works with students and postdoctoral researchers in the Network-Based Computing Laboratory, sharing insights culled from her expertise in science applications. She also assists the team in securing computer resource allocations and short-term reservations on OSC’s IBM 1350 Opteron cluster.
“Using our techniques, a seismic simulation application (AWP-ODC), can be sped up by 15 percent on 8,000 processor cores,” Tomko explained. “And, three-dimensional Fourier transforms can be improved up to 23 percent on 128 cores.”
--
Project lead: Dhabaleswar K. Panda, The Ohio State University
Research title: Design of advanced MPI features in MVAPICH2 and applications-level case studies
Funding sources: National Science Foundation, Department of Energy
Web site: nowlab.cse.ohio-state.edu/