
Within the Ohio State University’s Computational Memory Lab, Per Sederberg, Ph.D., studies the successes and failures of human memory. Part of his work includes developing computational models to link neural activity and behavior to guide experimental work.
Out of that work came the Mixed Effects for Large Datasets project, or MELD, a project that harnessed the powerful Oakley Cluster at the Ohio Supercomputer Center to benefit researchers who don’t have similar access to high performance computing.
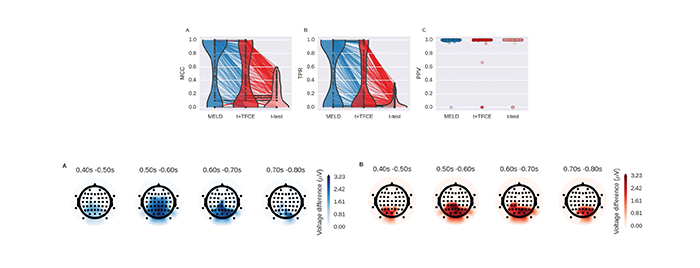
“In our initial evaluation of MELD, we focused on analysis of EEG (electroencephalography) data and found that it was much more sensitive than standard approaches,” Sederberg said. “The work here allows us to show MELD provides greater flexibility and sensitivity for a broad swath of the large datasets increasingly frequent in biomedical research.”
The problem with analyzing neural data sets, according to Dylan Nielson—a Ph.D. graduate student in neuroscience working for Sederberg—is it’s currently limited by the fact they’re too big.
“Generally speaking, you’re trying to find which part of the brain shows some difference between two conditions,” Nielson said. “So you might be trying to see which part of the brain is more active when someone is talking versus when they’re reading. To do that you have to make some comparison at every point in the brain, so these statistical tests take a long time to run.
“Our goal with MELD was to come up with a way to run a more statistical test across an entire giant neural dataset.”
These datasets are incredibly complex and validating the methods is time-consuming, meaning HPC capabilities were essential to developing MELD.
“Without HPC, it would have taken years and years to prove this method performs better than standard methods,” Nielson said. “MELD is a way to do really sophisticated statistics in a feasible amount of time without violating a lot of the assumptions standard techniques might violate.”
MELD is a technique that also could be beneficial to those outside neural science because of its ability to measure repeated behaviors over time.
“It’s a technique that is potentially really powerful for certain types of large data problems,” Nielson said. “So large populations of individuals over time—financial, housing, etc.—you could model at a market-by-market level across the country. So at every zip code, you could get a robust amount of estimates.”
Project Lead: Per Sederberg, Ph.D., The Ohio State University
Research Title: MELD—Mixed Effects for Large Datasets
Funding Source: The Ohio State University
Website: faculty.psy.ohio-state.edu/sederberg