Ohio Supercomputer Center
1224 Kinnear Road
Columbus, OH 43212
Ph: 1-614-292-9701
Fax: 1-614-292-7168
troy@osc.edu
http://www.osc.edu/~troy/
- ABSTRACT:
- This paper will describe OSC's experiences in using parallel I/O for scientific applications on a cluster of SGI 750 Itanium systems connected with Myrinet and Gigabit Ethernet. The target file systems include local disks on each node, NFS served by an SGI Origin 2000, and PVFS served by 16 Pentium III systems. The parallel I/O applications demonstrated include several standard I/O benchmarks (bonnie, ROMIO perf, NAS btio, and ASCI Flash) as well as user application codes.
- KEYWORDS:
- parallel, I/O, Itanium, cluster, benchmarking
- PRESENTATION SLIDES:
- https://www.osc.edu/sites/osc.edu/files/staff_files/troy/cug_2002-preso.pdf
Introduction
The 64-bit Intel Itanium processor is an ambitious new entry into the arena of high performance computing, and the Ohio Supercomputer Center (OSC) has been at the forefront of HPC centers investigating and adopting this new technology. OSC installed the first cluster of production Itanium systems, based on the SGI 750 workstation, in July 2001. This system quickly became popular with users and is one of the most heavily used systems at OSC.
While used primarily as a production computing resource, OSC's Itanium cluster also serves as a research testbed for high performance computing technology. One area of the research capacity of the system is that of parallel input/output techniques. This is an area of active research in the Linux cluster community; as cluster systems become larger and more capable, the need for high capacity and high performance storage increases. This paper describes efforts to benchmark the I/O performance of the Itanium cluster with respect to locally attached storage, shared storage using NFS, and shared storage using a parallel file system.
System Configuration
SGI 750 Cluster
OSC's Itanium cluster consists of a total of seventy-three SGI 750 systems running Linux. Each system contains two Itanium processors running at 733 MHz with 2 megabytes of L3 cache, 4 gigabytes of main memory, an 18 gigabyte SCSI system disk, an onboard 100 megabit Ethernet interface, and PCI-based Myrinet 2000 and Gigabit Ethernet interfaces. One system was designated as a "front end" node and file server and equipped with additional disks and Ethernet interfaces, while the other seventy-two systems act strictly as computational nodes, scheduled using PBS and Maui scheduler. Each computational node has approximately 5.3 gigabytes of space available on its local /tmp filesystem.
The presence of three network interfaces on each system is not accidental; indeed, it reflects part of OSC's cluster design philsophy, that administration, message passing, and I/O should each have its own network when possible. The 100 megabit Ethernet network is used for administration and low performance (NFS) file traffic, while the Myrinet network is dedicated to MPI message passing traffic. The Gigabit Ethernet network has two primary uses: high-performance file I/O traffic and research into implementing MPI at the network interface level [1]. This paper will focus on the high performance I/O application of the Gigabit Ethernet network.
I/O Infrastructure and Storage Systems
OSC's Gigabit Ethernet infrastructure is based around an Extreme Networks Black Diamond 6816 switch. All of OSC's HPC systems have at least one Gigabit Ethernet interface connected to this switch. In the case of OSC's HPC cluster systems, the front end nodes have direct Gigabit Ethernet connections to the switch, while compute nodes have 100 megabit Ethernet connections to one of several private switches internal to the cluster, each of which have Gigabit Ethernet uplinks to the Black Diamond switch. The Gigabit Ethernet interfaces on the Itanium cluster nodes are also directly connected to the Black Diamond switch and configured to use jumbo (9000 byte) frames instad of standard Ethernet frames. A separate HIPPI network is also used by several of the HPC systems for file service.
The primary mass storage server attached to this network is an Origin 2000 system, nicknamed mss. This eight processor system supports approximately one terabyte of Fibre Channel disk storage and an IBM 3494 tape robot containing roughly sixty terabytes of tape storage, managed by SGI's Data Migration Facility (DMF) software. The mss system is responsible for home directory and archival file service to OSC's various HPC systems, using NFS over the Gigabit Ethernet and HIPPI networks.
Also connected to the Gigabit Ethernet infrastructure is a sixteen node cluster dedicated to parallel file system research. Each node in this cluster contains two Intel Pentium III processors running at 933 MHz, a gigabyte of RAM, an onboard 100 megabit Ethernet interface, a PCI-based Gigabit Ethernet interface which supports jumbo frames, and a 3ware 7810 EIDE RAID controller driving eight eighty-gigabyte drives in a RAID 5 configuration. Using the PVFS software developed by Clemson University [2,3], the disk space on these systems is presented to client systems as a unified parallel file system with an aggregate capacity of 7.83 terabytes and a peak network transfer rate of 2 gigabytes per second. The PVFS file system can be accessed by parallel applications using the ROMIO implementation of the parallel I/O chapter of the MPI-2 specification [4] or by serial applications using a user-space VFS driver for the Linux kernel. Similar VFS drivers for other systems from vendors such as SGI and Cray are currently under investigation.
Benchmarks
bonnie
bonnie [5] is a widely used UNIX file system benchmark. It tests performance using the POSIX low level I/O functions read() and write(), as well as stream oriented character I/O using getc() and putc(). As a result, bonnie is a good indicator of the performance characteristics of sequential applications.
Unfortunately, bonnie also has two problems with respect to large, modern high performance systems. First, it uses a C int to store the size of the file it uses for testing, which limits it to a maximum file size of two gigabytes on systems on which an int is 32 bits, including Linux on the Itanium. Second, it uses an 8kB buffer for read() and write() operations, which is acceptable for file systems that have block sizes smaller than 8kB but disastrous for file systems like PVFS that have much larger block sizes. To compensate for these problems, the author developed a variation of the code called bigbonnie, which can handle files larger than two gigabytes and uses 64kB buffers.
Figure 1: Original bonnie Results
---------Sequential Output-------- ---Sequential Input--- ----Random---
-Per Char- ---Block--- -Rewrite-- -Per Char- ---Block--- ----Seeks----
Filesys MB K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU /sec %CPU
/tmp 2000 6099 99.2 262477 99.9 327502 99.9 3091 99.9 552000 99.9 90181.5 193.7
/home 2000 147 3.7 1562 2.3 859 1.7 1909 62.7 542824 99.9 805.5 3.0
/pvfs 2000 3909 63.5 199 1.1 201 2.4 2816 92.9 6614 36.3 227.2 12.1
|
Figure 2: bigbonnie Results
-------Sequential Output-------- ---Sequential Input-- --Random--
-Per Char- --Block--- -Rewrite-- -Per Char- --Block--- --Seeks---
Filesys MB MB/s %CPU MB/s %CPU MB/s %CPU MB/s %CPU MB/s %CPU /sec %CPU
/tmp 4096 5.9 99.6 24.6 10.1 17.2 7.1 3.9 96.6 34.2 9.7 452.9 6.8
/home 8192 0.1 3.2 1.5 2.0 0.8 1.4 1.7 42.3 3.0 1.8 74.6 3.5
/pvfs 8192 3.8 63.3 11.0 7.3 16.0 25.7 3.4 91.2 32.8 25.6 583.3 30.1
|
Figures 1 and 2 show the results of bonnie and bigbonnie when used on three file systems: /tmp on a node's local disk, /home mounted via NFS from the mass storage server, and /pvfs mounted using the Linux user-space PVFS driver from the parallel file system cluster. The results with original bonnie are problematic, because the two gigabyte file size limit means that the largest file which the program can create is smaller than the main memory available on a node. This is why the original bonnie shows bandwidths in the hundreds of megabytes per second to /tmp; the file operations are being cached entirely in main memory, so the bandwidths observed are more in line with the performance of memory than the SCSI disk where /tmp physically resides. With the larger file sizes available to bigbonnie, these cache effects are greatly reduced.
Another noteworthy difference between the bonnie and bigbonnie results is the much higher performance of bigbonnie for block writes and rewrites, especially with respect to the PVFS file system. This is caused by bigbonnie's use of 64 kB records; in the case of the original bonnie, 8 kB records are used for block reads and writes, and this size turns out to be a pathological case for PVFS.
Given the poor performance of NFS demonstrated here and the limited size of the /tmp file systems on the SGI 750 compute nodes, all further benchmarks were only run against the PVFS file system.
ROMIO perf
The ROMIO source code includes an example MPI-IO program called perf. In this program, each MPI process has a fixed size data array, four megabytes by default, which is written using MPI_File_write() and read using MPI_File_read() to a fixed location equal to the process' rank times the size of the data array. There are two variations to each read and write test: one in which the time for a call to MPI_File_sync() is included in the timings (before read operations and after write operations), and one in which it is not. These tests provide an upper bound on the MPI-IO performance that can be expected from a given computer and file system.
Figure 3: perf Read with Sync Performance
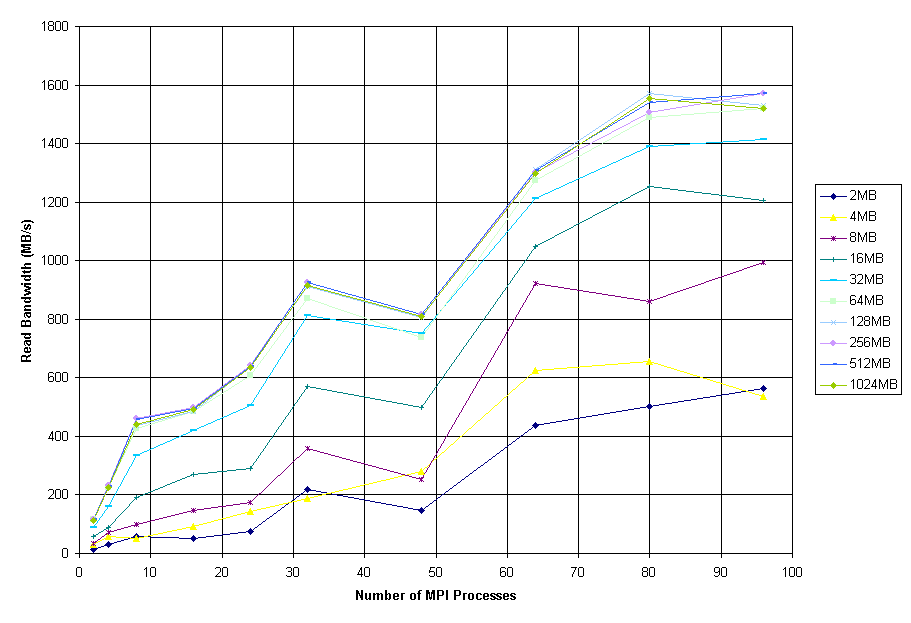
Figure 4: perf Write with Sync Performance
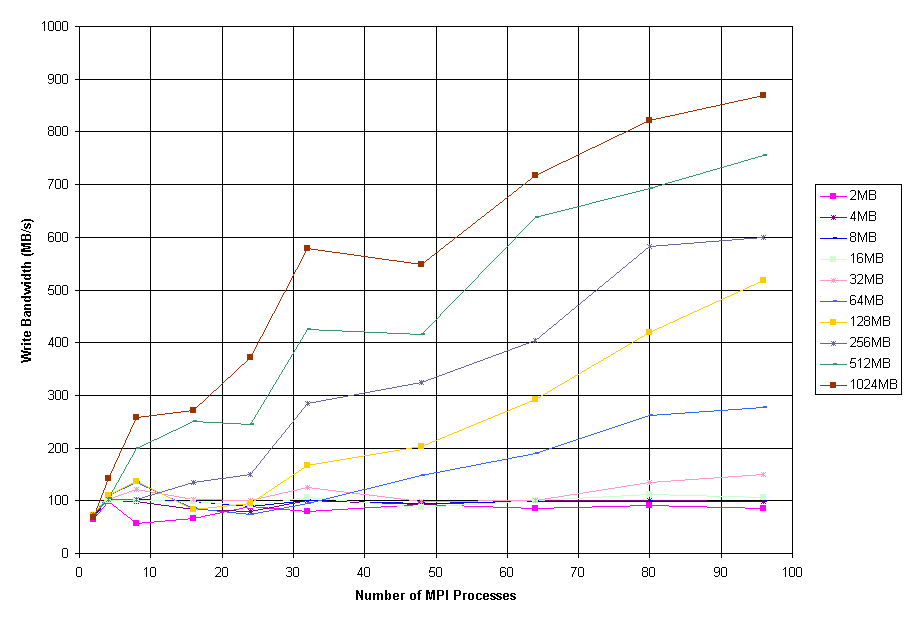
Figure 5: perf Write without Sync Performance
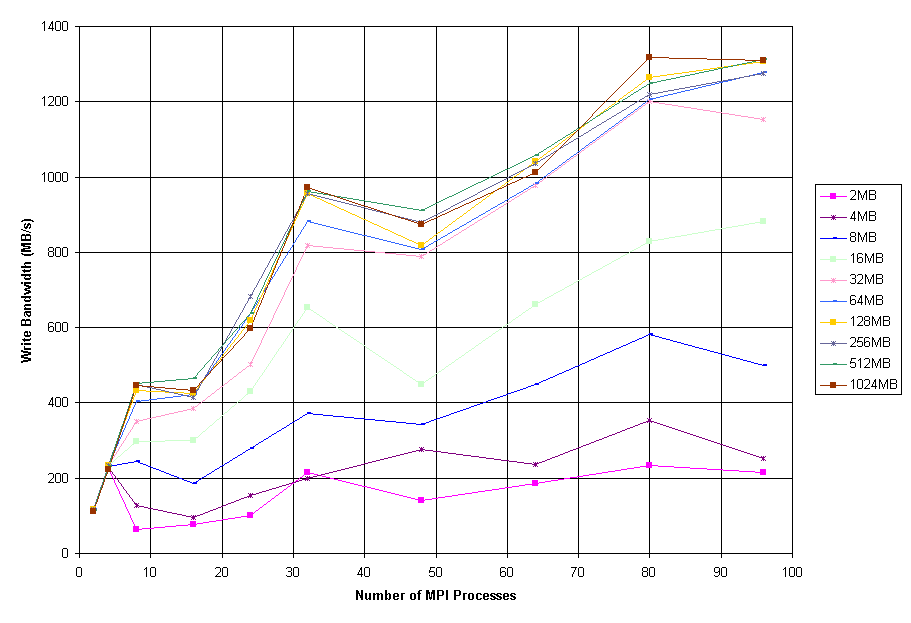
Figures 3 through 5 show the aggregate bandwidth reported by perf using array sizes from 2 MB to 1 GB for the cases of reads preceded by MPI_File_sync(), writes followed by MPI_File_sync(), and writes without a sync respectively. The cases of read and write-without-sync both show peak bandwidths of approximately 1.5 GB/s, while the case of write-with-sync peaks at 870 MB/s. All three cases show their best performance with very large array sizes; in the case of write-with-sync, array sizes of 32 MB and below rarely exceed 100 to 150 MB/s, even for large process counts, but array sizes of 64 MB and above scale favorably. All the curves shown also exhibit drops in performance at process counts of 24 and 48; this is thought to be caused by saturation of the Gigabit Ethernet network. The Itanium compute nodes are connected to 12-port Gigabit Ethernet line cards in the Extreme Networks 6816, and these line cards are known to have a maximum bandwidth to the switch backplane of only 4 Gbit/s, whereas the 8-port line cards to which the I/O nodes are connected have a maximum bandwidth to the backplane of 8 Gbit/s. In cases where the 12-port line cards are heavily utilized, performance is somewhat degraded.
NAS btio
The btio benchmarks are variations on the well known bt application benchmark from the NAS Parallel Benchmark suite, developed at NASA Ames Research Center [6]. The base bt application solves systems of block-tridiagonal equations in parallel; the btio benchmarks add several different methods of doing periodic solution checkpointing in parallel, including Fortran direct unformatted I/O, MPI-IO using several calls to MPI_File_write_at() (known as the "simple" MPI-IO version), and MPI-IO using an MPI data type and a single call to MPI_File_write_at() (the "full" MPI-IO version).
Figure 6: NAS btio Performance
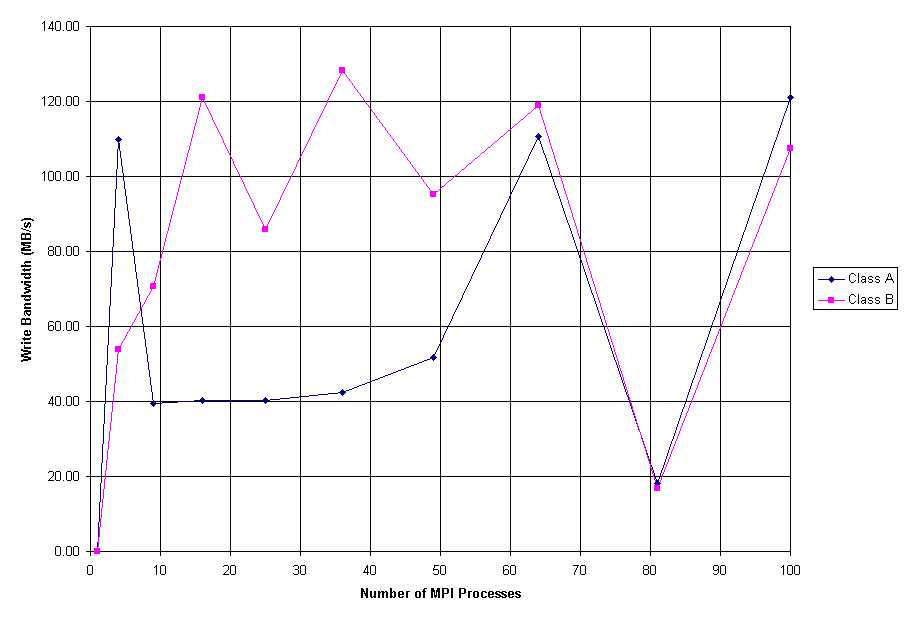
Figure 6 shows the performance observed using class A (623 volume) and class B (1023 volume) configurations of the full MPI-IO variant of btio which has been instrumented to measure I/O bandwidth. The class A configurations averaged about 40 MB/s, while the class B configurations averaged about 100 MB/s. Class C (1623 volume) configurations would not run due to a bug in the ROMIO code with the version of MPICH/ch_gm in use on the system. Both class A and class B configurations show significant drops in performance at odd process counts however, with the worst being observed at 81 processes.
ASCI Flash I/O
ASCI Flash is a parallel application that simulates astrophysical thermonuclear flashes developed at the University of Chicago and used in the U.S. Department of Energy Accelerated Strategic Computing Initiative (ASCI) program [7]. It uses the MPI-IO parallel interface to the HDF5 data storage library to store its output data, which consists of checkpoints as well as two types of plottable data. The I/O portion of this application is sufficiently large that the developers have separated it into a separate code, known as the ASCI Flash I/O benchmark, for testing and tuning purposes [8]. The ASCI Flash I/O benchmark has been run on a number of platforms, including several of the ASCI teraflop-scale systems as well as the Chiba City cluster at Argonne National Laboratory [9], which, like OSC's Itanium cluster, uses PVFS for its parallel file system.
Figure 7: Flash I/O Performance
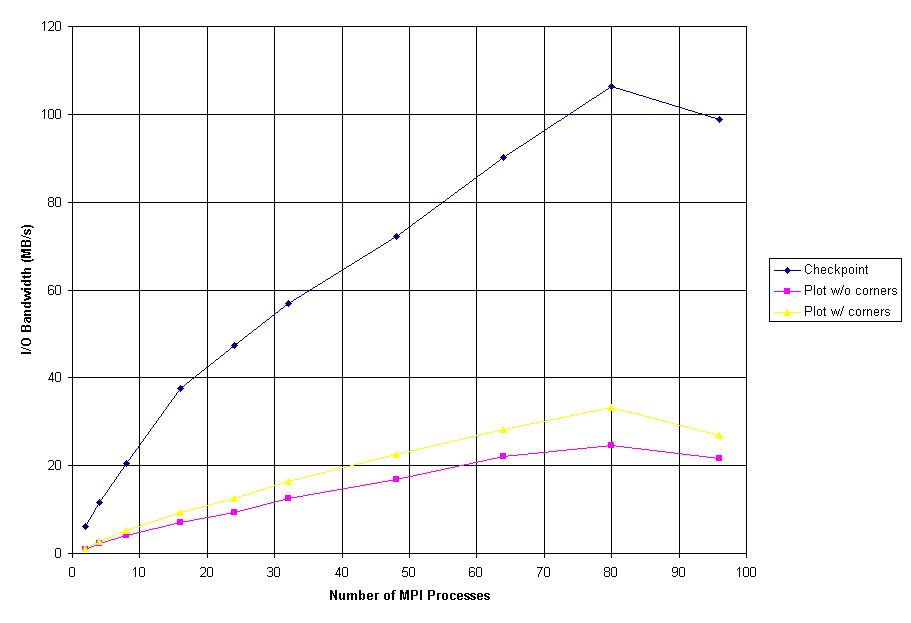
Figure 7 shows the performance of the ASCI Flash I/O benchmark on OSC's Itanium cluster. As seen in Argonne's studies with Flash I/O to PVFS on Chiba City, the total I/O time is dominated by data type processing. Flash I/O stores all of the data for a given point together in its output files, while in memory it stores adjacent values of the same quality together; the overhead associated with the rearrangement from the way data is layed out in memory to how it is layed out in the files has been observed to be quite large. The results seen on OSC's Itanium cluster are quite competitive with the ASCI systems; only the IBM SP system "Frost" at Lawrence Livermore National Laboratory demonstrates higher performance, and then only at process counts of 256 and above [8].
2D Laplace Solver
The Science and Technology Support group at OSC has developed a series of Fortran codes that solve Laplace's equation on a two-dimensional grid of fixed size. These codes are used primarily as examples in teaching concepts of application performance tuning and parallel computing approaches, such as vectorization [10], OpenMP, MPI, and hybrid OpenMP/MPI [11]. A natural extension of an MPI version of these codes was to add MPI-IO calls to write a checkpoint file, which was done in support of a workshop offered by OSC on parallel I/O techniques [12]. Several variations of this code exist; the best performing of them uses a call to MPI_File_write_all() after seeking to separate regions of the file to accomplish its output.
Figure 8: Laplace Solver I/O Performance
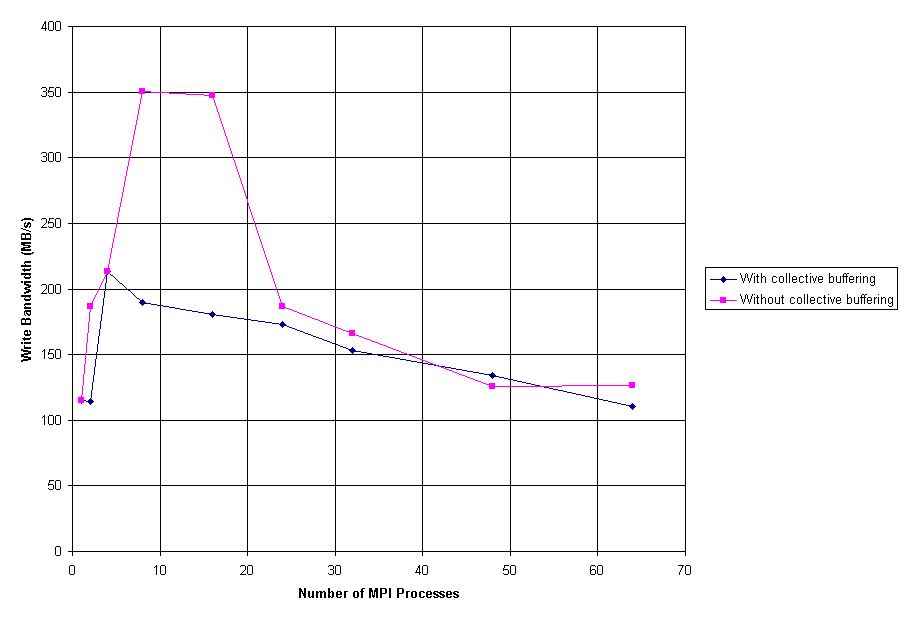
Figure 8 shows the I/O performance of the MPI Laplace solver application on an 8001x8001 grid (approximately 0.5 GB) for two cases, one using buffering of collective I/O and one without collective buffering. Collective buffering is a parallel I/O optimization in which the data being written is reorganized into contiguous segments before it is set to the I/O subsystem, but in this case the data being written is already contiguous and hence collective buffering is unnecessary overhead. The bandwidth exhibited by this application does not scale well beyond 16 processors; this is because as the process count increases, the amount of data being written by an individual process drops because of the fixed grid size. This means that the performance drops from following the 512 MB curve from Figure 5 (in the case of 1-2 processes) to following the 8 MB curve from the same figure (in the case of 64 processes).
Conclusions and Future Work
These benchmarks demonstrate that PVFS on Itanium-based systems can perform very well for applications using MPI-IO, and roughly the same as a local disk for applications using conventional POSIX I/O when writing large blocks of data. Unfortunately, while it is a good candidate for high performance temporary storage, PVFS is not necessarily a good general purpose file system. Its RAID-0 like nature means that the catastrophical failure of an I/O node can destroy the file system; however, this can be mitigated to some extent by having onsite spares, and work is ongoing to add RAID-10 like behavior at both the file system and file level. Also, metadata operations such as fstat() on PVFS are very expensive, because the PVFS metadata manager daemon must communicate with each I/O daemon.
OSC has further plans for investigating parallel I/O on Linux clusters on several fronts. First among these is to connect the parallel file system to the center's Athlon-based IA32 cluster, using either 100Mbit Ethernet or possibly Myrinet 2000 as the I/O network. Also, there are a few more parallel I/O benchmarks which should be run against the parallel file system, such as the effective I/O bandwidth benchmark b_eff_io [13] and the LLNL Scalable I/O Project's ior_mpiio [14]. Also, the effect of collective buffering on the "full" version of the NAS btio benchmark needs to be investigated, as collective buffering could improve its performance significantly.
References
- [1]
- P. Shivam, P. Wyckoff, and D. Panda. EMP: Zero-copy OS-bypass NIC-driven Gigabit Ethernet Message Passing, Proceedings of Supercomputing 2001. ACM/IEEE, 2001.
- [2]
- P. Carns, W. Lignon, R. Ross, and R. Thakur. PVFS: A Parallel File System for Linux Clusters, Proceedings of the Fourth Annual Linux Showcase and Conference. 2000.
- [3]
- R. Ross. Providing Parallel I/O on Linux Clusters (presentation), Second Annual Linux Storage Management Workshop. 2000.
- [4]
- R. Thakur, W. Gropp, and E. Lusk. On Implementing MPI-IO Portably and with High Performance, Proceedings of the Sixth Workshop on I/O in Parallel and Distributed Systems. ACM, 1999.
- [5]
- T. Bray. Bonnie,
http://www.textuality.com/bonnie/. 2000. - [6]
- NAS Application I/O (BTIO) Benchmark,
http://parallel.nas.nasa.gov/MPI-IO/btio. NASA Ames Research Center, 1996. - [7]
- ASCI Center for Astrophysical Thermonuclear Flashes,
http://www.flash.uchicago.edu/research/science.html. University of Chicago, 2001. - [8]
- M. Zingale. Flash I/O Benchmark Routine -- Parallel HDF5,
http://www.ucolick.org/~zingale/flash_benchmark_io/. University of Chicago, 2001. - [9]
- R. Ross, D. Nurmi, A. Cheng, and M. Zingale. A Case Study in Application I/O on Linux Clusters, Proceedings of Supercomputing 2001. ACM/IEEE, 2001.
- [10]
- J. Giuliani and D. Robertson. Performance Tuning for Vector Architectures,
http://oscinfo.osc.edu/training/perftunvec/. OSC, 2001. - [11]
- T. Baer and D. Ennis. Multilevel Parallel Programming,
http://oscinfo.osc.edu/training/multi/. OSC, 2000. - [12]
- T. Baer. Parallel I/O Techniques,
http://oscinfo.osc.edu/training/pario/. OSC, Columbus, OH, 2002. - [13]
- R. Rabenseifner and A.E. Koniges. The Effective I/O Bandwidth Benchmark (b_eff_io), Proceedings of the Message Passing Interface Developer's Conference 2000. Ithaca, NY, 2000.
- [14]
- The IOR README File,
http://www.llnl.gov/asci/purple/benchmarks/limited/ior/ior.mpiio.readme.html. Lawrence Livermore National Laboratory, Livermore, CA, 2001.
About the Author
Troy Baer received his M.S. in aerospace engineering in 1998. Since then, he has worked in the Science and Technology Support group at the Ohio Supercomputer Center (OSC), where he has developed numerous workshop courses on topics related to high performance computing. He has also been involved in OSC's cluster development group. His research interests include parallel I/O, scheduling for cluster systems, and performance analysis tools.