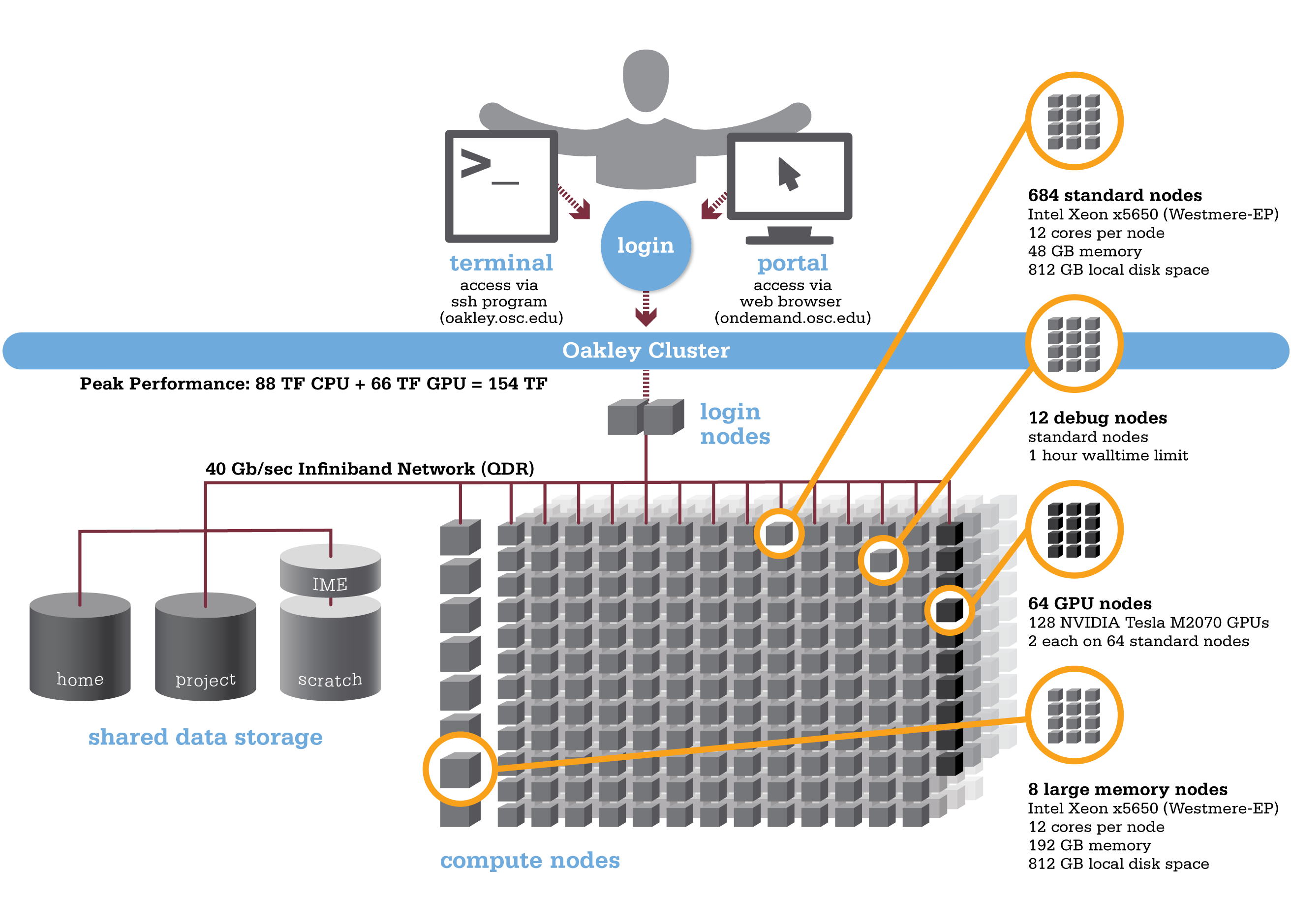
Oakley is an HP-built, Intel® Xeon® processor-based supercomputer, featuring more cores (8,328) on half as many nodes (694) as the center’s former flagship system, the IBM Opteron 1350 Glenn Cluster. The Oakley Cluster can achieve 88 teraflops, tech-speak for performing 88 trillion floating point operations per second, or, with acceleration from 128 NVIDIA® Tesla graphic processing units (GPUs), a total peak performance of just over 154 teraflops.
Hardware
 Detailed system specifications:
Detailed system specifications:
- 8,328 total cores
- Compute Node:
- HP SL390 G7 two-socket servers with Intel Xeon x5650 (Westmere-EP, 6 cores, 2.67GHz) processors
- 12 cores/node & 48 gigabytes of memory/node
- GPU Node:
- 128 NVIDIA Tesla M2070 GPUs
- 873 GB of local disk space in '/tmp'
- QDR IB Interconnect (40Gbps)
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 88.6 teraflops
- GPU acceleration
- Additional 65.5 teraflops
- Total peak performance
- 154.1 teraflops
- Memory Increase
- Increases memory from 2.5 gigabytes per core of Glenn system to 4.0 gigabytes per core.
- System Efficiency
- 1.5x the performance of former Glenn system at just 60 percent of current power consumption.
How to Connect
-
SSH Method
To login to Oakley at OSC, ssh to the following hostname:
oakley.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@oakley.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Oakley login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Oakley at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Oakley Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Oakley are 12 cores/processors per node (ppn). Parallel jobs must use
ppn=12. -
If you need more than 48 GB of RAM per node, you may run on the 8 large memory (192 GB) nodes on Oakley ("bigmem"). You can request a large memory node on Oakley by using the following directive in your batch script:
nodes=XX:ppn=12:bigmem, where XX can be 1-8. - We have a single huge memory node ("hugemem"), with 1 TB of RAM and 32 cores. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node.
nodes=1:ppn=32 with a walltime of 48 hours or less, and the scheduler will put you on the 1 TB node.- GPU jobs may request any number of cores and either 1 or 2 GPUs. Request 2 GPUs per a node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=12:gpus=2
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.