New! Online Training Courses
Check out our new online training courses for an introduction to OSC services. You can get more information on the OSC Training page.
Overview
HPC, or High Performance Computing, generally refers to aggregating computing resources together in order to perform more computing operations at once.
Basic definitions
- Core (processor) - A single unit that executes a single chain of instructions.
- Node - a single computer or server.
- Cluster - many nodes connected together which are able to coordinate between themselves.
HPC Workflow
Using HPC is a little different from running programs on your desktop. When you login you’ll be connected to one of the system’s “login nodes”. These nodes serve as a staging area for you to marshal your data and submit jobs to the batch scheduler. Your job will then wait in a queue along with other researchers' jobs. Once the resources it requires become available, the batch scheduler will then run your job on a subset of our hundreds of “compute nodes”. You can see the overall structure in the diagram below.
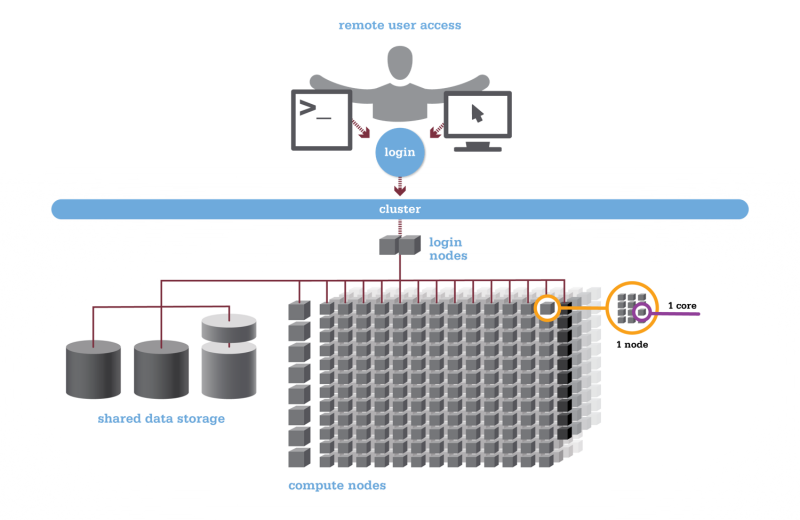
HPC Citizenship
An important point about the diagram above is that OSC clusters are a collection of shared, finite resources. When you connect to the login nodes, you are sharing their resources (CPU cycles, memory, disk space, network bandwidth, etc.) with a few dozen other researchers. The same is true of the file servers when you access your home or project directories, and can even be true of the compute nodes.
For most day-to-day activities you should not have to worry about this, and we take precautions to limit the impact that others might have on your experience. That said, there are a few use cases that are worth watching out for:
-
The login nodes should only be used for light computation; any CPU- or memory-intensive operations should be done using the batch system. A good rule of thumb is that if you wouldn't want to run a task on your personal desktop because it would slow down other applications, you shouldn't run it on the login nodes. (See also: Interactive Jobs.)
-
I/O-intensive jobs should copy their files to fast, temporary storage, such as the local storage allocated to jobs or the Scratch parallel filesystem.
-
When running memory-intensive or potentially unstable jobs, we highly recommend requesting whole nodes. By doing so you prevent other users jobs from being impacted by your job.
-
If you request partial nodes, be sure to consider the amount of memory available per core. (See: HPC Hardware.) If you need more memory, request more cores. It is perfectly acceptable to leave cores idle in this situation; memory is just as valuable a resource as processors.
In general, we just encourage our users to remember that what you do may affect other researchers on the system. If you think something you want to do or try might interfere with the work of others, we highly recommend that you contact us at oschelp@osc.edu.