OSC's original Pitzer cluster was installed in late 2018 and is a Dell-built, Intel® Xeon® 'Skylake' processor-based supercomputer with 260 nodes.
In September 2020, OSC installed additional 398 Intel® Xeon® 'Cascade Lake' processor-based nodes as part of a Pitzer Expansion cluster.
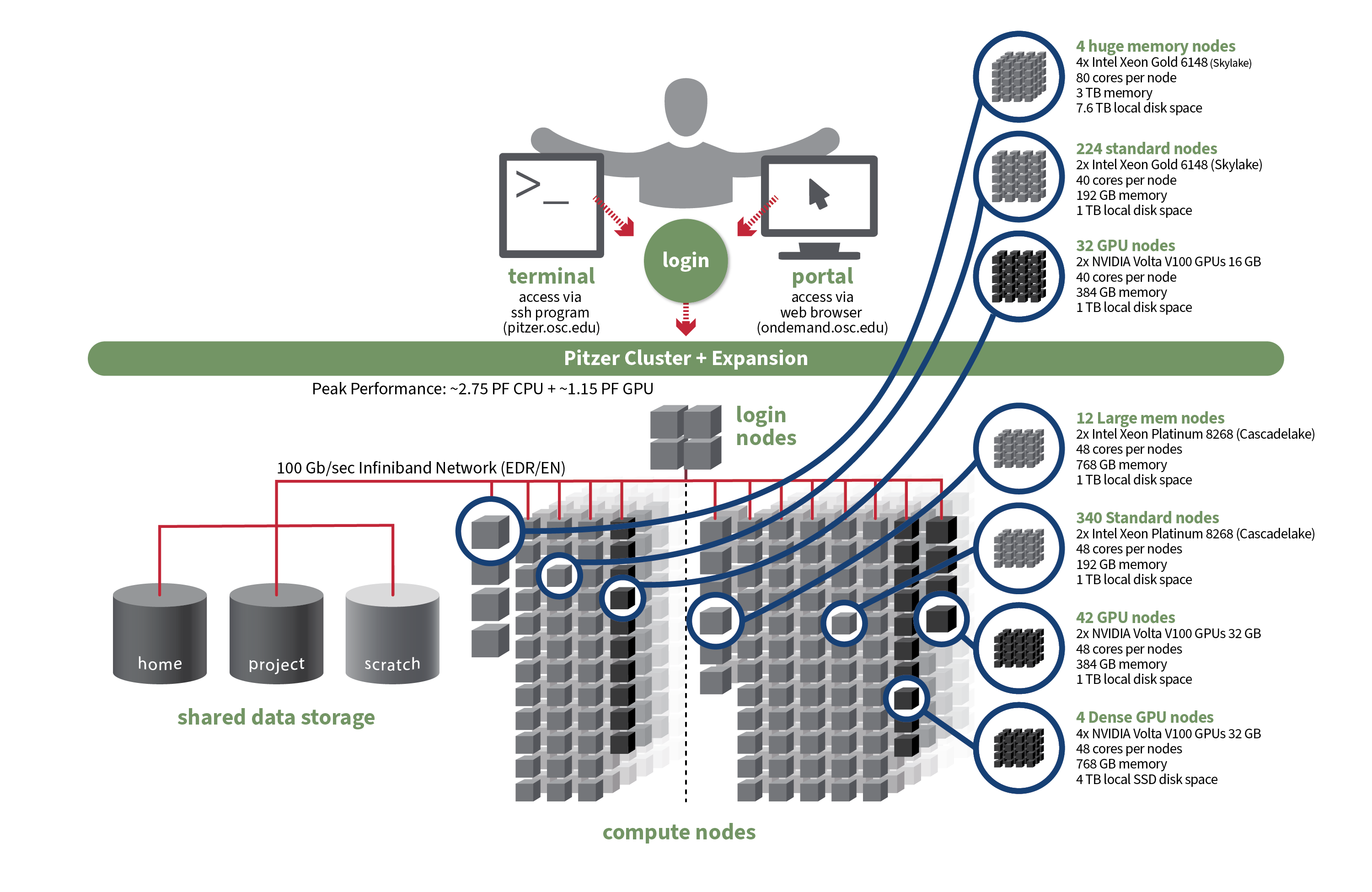
Hardware

Detailed system specifications:
| Deployed in 2018 | Deployed in 2020 | Total | |
|---|---|---|---|
| Total Compute Nodes | 260 Dell nodes | 398 Dell nodes | 658 Dell nodes |
| Total CPU Cores | 10,560 total cores | 19,104 total cores | 29,664 total cores |
| Standard Dense Compute Nodes |
224 nodes
|
340 nodes
|
564 nodes |
| Dual GPU Compute Nodes | 32 nodes
|
42 nodes
|
74 dual GPU nodes |
| Quad GPU Compute Nodes | N/A | 4 nodes
|
4 quad GPU nodes |
| Large Memory Compute Nodes | 4 nodes
|
12 nodes
|
16 nodes |
| Interactive Login Nodes |
4 nodes
|
4 nodes | |
| InfiniBand High-Speed Network | Mellanox EDR (100 Gbps) Infiniband networking | Mellanox EDR (100 Gbps) Infiniband networking | |
| Theoretical Peak Performance |
~850 TFLOPS (CPU only) ~450 TFLOPS (GPU only) ~1300 TFLOPS (total) |
~1900 TFLOPS (CPU only) ~700 TFLOPS (GPU only) ~2600 TFLOPS (total) |
~2750 TFLOPS (CPU only) ~1150 TFLOPS (GPU only) ~3900 TFLOPS (total) |
How to Connect
-
SSH Method
To login to Pitzer at OSC, ssh to the following hostname:
pitzer.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@pitzer.osc.edu
You may see a warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprints listed here, then type yes.
From there, you are connected to the Pitzer login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Pitzer at OSC with our OnDemand tool. The first step is to log into OnDemand. Then once logged in you can access Pitzer by clicking on "Clusters", and then selecting ">_Pitzer Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
File Systems
Pitzer accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the old clusters. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system on Pitzer is the same as on the Owens and Ruby systems. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the modules that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider . By default, you will have the batch scheduling software modules, the Intel compiler, and an appropriate version of mvapich2 loaded.
You can keep up to the software packages that have been made available on Pitzer by viewing the Software by System page and selecting the Pitzer system.
Compiling Code to Use Advanced Vector Extensions (AVX2)
The Skylake processors that make Pitzer support the Advanced Vector Extensions (AVX2) instruction set, but you must set the correct compiler flags to take advantage of it. AVX2 has the potential to speed up your code by a factor of 4 or more, depending on the compiler and options you would otherwise use.
In our experience, the Intel and PGI compilers do a much better job than the gnu compilers at optimizing HPC code.
With the Intel compilers, use -xHost and -O2 or higher. With the gnu compilers, use -march=native and -O3 . The PGI compilers by default use the highest available instruction set, so no additional flags are necessary.
This advice assumes that you are building and running your code on Pitzer. The executables will not be portable. Of course, any highly optimized builds, such as those employing the options above, should be thoroughly validated for correctness.
See the Pitzer Programming Environment page for details.
Batch Specifics
Refer to this Slurm migration page to understand how to use Slurm on the Pitzer cluster. Some specifics you will need to know to create well-formed batch scripts:
- OSC enables PBS compatibility layer provided by Slurm such that PBS batch scripts that used to work in the previous Torque/Moab environment mostly still work in Slurm.
- Pitzer is a heterogeneous system with mixed types of CPUs after the expansion as shown in the above table. Please be cautious when requesting resources on Pitzer and check this page for more detailed discussions
- Jobs on Pitzer may request partial nodes.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC and Slurm migration. For specific information about modules and file storage, please see the Batch Execution Environment page.